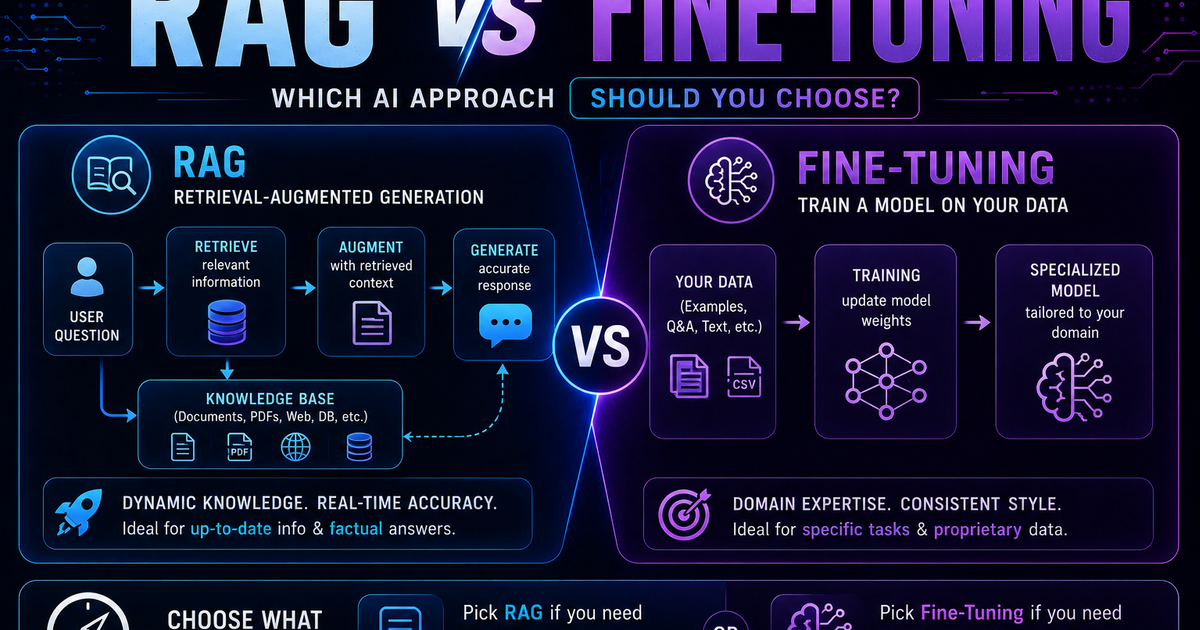
RAG vs Fine-Tuning: Which AI Approach Should You Choose?
RAG vs fine-tuning in 2026 — a practical guide covering when to use each, how both work with real code examples, the form vs facts distinction, hybrid approaches, true costs, and a decision framework to choose the right AI architecture for your use case.
Most teams asking about fine-tuning should not fine-tune.
That's the honest starting point from practitioners who have shipped production AI systems in 2026. Teams reach for fine-tuning because it feels like the serious, professional approach — the thing real AI companies do. But most of the time, the prerequisite work hasn't been done, and fine-tuning is the wrong answer to a problem that should have been solved earlier in the stack.
The right sequence in 2026 is: better prompts → RAG → fine-tuning → distillation. Fine-tuning sits third in that progression, not first. Teams that get this right ship reliable AI products faster. Teams that get it wrong burn months on expensive training runs that should have been a retrieval pipeline.
This guide explains both approaches clearly, where each one genuinely excels, the specific questions that determine which one fits your situation, and the emerging hybrid approach that is becoming the production default for teams that need both. By the end, you'll have a clear decision framework — not a vague "it depends" but a concrete set of tests you can apply to your actual use case.
The one-sentence version of each approach
RAG (Retrieval-Augmented Generation) — the model stays unchanged; you give it relevant information at query time by retrieving it from an external knowledge source.
Fine-tuning — the model's parameters are updated by further training on a curated dataset, permanently changing its behaviour, style, or domain knowledge.
The deepest way to understand the difference: RAG changes what the model can see right now. Fine-tuning changes what the model is.
Everything else in this comparison flows from that distinction.
How RAG works
A RAG system adds a retrieval step before generation. Instead of asking the model to answer from its training knowledge alone, the system first searches an external knowledge base for relevant content, injects that content into the model's context window, and then asks the model to generate a response grounded in what it just retrieved.
The basic architecture:
User query
↓
Embed the query into a vector
↓
Search a vector database for the most semantically similar chunks
↓
Retrieve the top-k chunks (documents, paragraphs, records)
↓
Inject retrieved chunks + original query into the model's prompt
↓
Model generates a response grounded in the retrieved context
↓
Return response to user
In code, the core retrieval step looks like this:
from openai import OpenAI
import numpy as np
client = OpenAI()
def retrieve_relevant_chunks(query: str, knowledge_base: list, top_k: int = 5):
# Embed the user's query
query_embedding = client.embeddings.create(
model="text-embedding-3-small",
input=query
).data[0].embedding
# Find the most similar chunks by cosine similarity
scores = []
for chunk in knowledge_base:
similarity = np.dot(query_embedding, chunk["embedding"])
scores.append((similarity, chunk["text"]))
# Return the top-k most relevant chunks
scores.sort(reverse=True)
return [text for _, text in scores[:top_k]]
def rag_query(user_question: str, knowledge_base: list) -> str:
relevant_chunks = retrieve_relevant_chunks(user_question, knowledge_base)
context = "\n\n".join(relevant_chunks)
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": "Answer the user's question based only on the provided context. "
"If the answer is not in the context, say so."
},
{
"role": "user",
"content": f"Context:\n{context}\n\nQuestion: {user_question}"
}
]
)
return response.choices[0].message.content
The knowledge base itself is typically built by chunking your documents, embedding each chunk, and storing the embeddings in a vector database — Pinecone, Weaviate, Qdrant, or pgvector if you're already on PostgreSQL.
What RAG does well:
- The knowledge base can be updated instantly — add a document, re-embed it, and the system can answer questions about it immediately
- The model's core capabilities (reasoning, writing, code) are fully preserved
- Responses can cite their sources, making them verifiable and auditable
- No training cost — you pay only for embeddings and inference
- Works with any foundation model, including the latest and most capable ones
Where RAG struggles:
- Retrieval quality limits answer quality — if the right chunk isn't retrieved, the model can't answer correctly
- Doesn't change the model's output style, tone, or format
- Context window limits cap how much retrieved content can be used
- Latency is higher than a direct model call due to the retrieval step
- Requires careful chunking strategy — too large and you retrieve noise, too small and you lose context
How fine-tuning works
Fine-tuning takes a pre-trained foundation model and continues training it on a curated, task-specific dataset. The model's parameters are updated — it learns new patterns, adjusts its style, and internalises domain-specific behaviour. After fine-tuning, the model behaves differently without needing any external context.
The practical reality in 2026: LoRA and QLoRA are the only fine-tuning approaches most teams should consider. Full fine-tuning (updating every parameter in a large model) requires enormous compute and risks catastrophic forgetting — the model loses general capabilities as it learns specialised ones. LoRA (Low-Rank Adaptation) adds small trainable adapters to the model without modifying the original weights, dramatically reducing compute requirements and preserving the base model's capabilities.
# Fine-tuning with LoRA using the HuggingFace PEFT library
from peft import LoraConfig, get_peft_model, TaskType
from transformers import AutoModelForCausalLM, TrainingArguments, Trainer
# Load the base model
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3-8b")
# Configure LoRA — only a small fraction of parameters are trained
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=16, # Rank — controls adapter size
lora_alpha=32, # Scaling factor
lora_dropout=0.1,
target_modules=["q_proj", "v_proj"] # Which layers to adapt
)
# Apply LoRA to the model
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# Output: trainable params: 4,194,304 || all params: 8,003,534,080
# Only 0.05% of parameters are updated — the base model is preserved
# Training configuration
training_args = TrainingArguments(
output_dir="./fine-tuned-model",
num_train_epochs=3,
per_device_train_batch_size=4,
learning_rate=2e-4,
fp16=True # Mixed precision for memory efficiency
)
QLoRA goes further — it quantises the base model to 4-bit precision before adding LoRA adapters, making it possible to fine-tune a 70B parameter model on a single consumer GPU. For most teams in 2026, QLoRA is the most practical entry point to fine-tuning large models without enterprise-scale compute.
What fine-tuning does well:
- Permanently changes the model's output style, tone, and format — the only way to truly reshape how a model responds
- Internalises stable domain patterns — medical terminology, legal reasoning patterns, financial analysis frameworks
- Improves structured output reliability — JSON schema adherence, classification consistency, following specific formatting rules
- No retrieval latency — the model answers directly from its weights
- Cost-effective at high inference volume once training is amortised
Where fine-tuning struggles:
- Knowledge cut-off — the model only knows what was in the training data; updating knowledge requires retraining
- Data requirements — quality training data is expensive to curate; low-quality data produces worse outputs
- Catastrophic forgetting — fine-tuning risks degrading the model's general capabilities if not done carefully
- Operational overhead — adapter versioning, retraining cadence, base model drift management are recurring costs
- When a hosted provider updates their base model, your adapter may degrade silently. Plan quarterly revalidation.
The critical distinction: form vs facts
The most important principle in the entire RAG vs fine-tuning decision is this one, from practitioners who have gotten it wrong:
Fine-tuning is for form, not facts. Use RAG for knowledge that changes; use fine-tuning for stable behavior, schema, and tone.
This maps precisely onto the two failure modes that send teams down the wrong path:
If your failure mode is factual: The model gives outdated answers, doesn't know about recent events, can't access your proprietary documents, or answers questions it doesn't have knowledge for — this is a RAG problem, not a fine-tuning problem. Fine-tuning cannot inject fresh, dynamic knowledge. It bakes in whatever was in the training data at training time.
If your failure mode is behavioural: The model uses the wrong tone, produces inconsistently formatted output, doesn't follow your classification schema reliably, doesn't adhere to your brand voice, or behaves inconsistently in ways that affect user trust — this is a fine-tuning problem. RAG cannot fix behaviour. Adding more context doesn't change how a model fundamentally responds.
Getting this distinction wrong is the most expensive mistake teams make. You cannot fine-tune your way to freshness. You cannot RAG your way to a consistent brand voice.
When to use RAG
RAG is the right choice when:
Your knowledge changes frequently. Product documentation, legal policies, research papers, support articles, pricing information, inventory — anything that changes on a daily, weekly, or monthly basis. RAG lets you update your knowledge base without retraining. Fine-tuning would require a retraining run every time something changed.
You need source attribution. In regulated industries, enterprise applications, and any context where users need to verify answers, RAG lets you cite the specific document a response is based on. Fine-tuned model outputs are not traceable to specific source documents.
You're working with private or proprietary data. RAG retrieves from your own secure knowledge base. The foundation model never needs to be trained on your sensitive data — it only sees retrieved chunks at inference time.
You want to use the best available model. RAG works with any model, including the latest and most capable frontier models. Fine-tuning locks you into a specific model version; when a better model is released, you'd need to retrain. With RAG, you swap the underlying model with minimal changes to the retrieval layer.
Your budget is constrained. RAG requires no training compute. The costs are embedding generation (one-time per document) and inference. Fine-tuning requires compute for training, validation, and ongoing retraining runs.
Real-world examples where RAG excels:
- Customer support chatbot with a product documentation knowledge base
- Internal Q&A system over company policies and HR documents
- Research assistant with access to a specific academic paper corpus
- Legal assistant querying a contract library
- Sales assistant with current product and pricing information
When to use fine-tuning
Fine-tuning is the right choice when:
You need consistent output behaviour at scale. If your application requires every response to follow a specific format — a particular JSON schema, a specific markdown structure, a classification into exactly these five categories — fine-tuning trains the model to follow that format reliably. Prompting achieves this inconsistently; RAG doesn't affect it at all.
Your domain has stable, specialised patterns. Medical diagnostic reasoning, legal clause analysis, financial modelling, code generation for a specific internal framework — domains with stable, deep patterns that general models handle weakly. Fine-tuning internalises those patterns. For highly specialized tasks, a fine-tuned model often outperforms a general model using RAG because it has deeply internalized the domain's patterns.
You need to permanently change tone or style. Brand voice consistency — if every response must sound like your company, not like a generic AI assistant. Fine-tuning is the only way to bake this in at the model level.
Latency is critical. Fine-tuned models respond at base inference speed with no retrieval step. For high-volume, latency-sensitive applications where the 100–300ms retrieval overhead is unacceptable, fine-tuning has an architectural advantage.
You're running high-volume inference at scale. Fine-tuning training costs are amortised over inference volume. At very high volumes — millions of daily calls to the same specialised task — a fine-tuned smaller model can be significantly cheaper per call than a large foundation model called with a lengthy context.
Real-world examples where fine-tuning excels:
- Medical coding assistant that must output ICD-10 codes in a specific format
- Legal contract classifier trained to identify clauses by type with high precision
- Customer service bot that must always match a specific brand tone
- Code generation model for a proprietary internal framework with unique conventions
- Classification model for support ticket routing with a fixed taxonomy
The 2026 decision framework
Before choosing between RAG and fine-tuning, work through this sequence of questions:
Step 1: Have you optimised your prompts first?
Many teams that think they need fine-tuning actually need better system prompts. A well-crafted system prompt with clear instructions, examples, and output specifications can achieve 70–80% of what fine-tuning would accomplish — at zero training cost. If you haven't tried structured prompting with a few-shot examples, do that first.
Step 2: Is the failure mode factual or behavioural?
Answer this question precisely. If your model gives wrong or outdated answers → RAG. If your model gives correct information in the wrong format, wrong tone, or inconsistently → fine-tuning.
Step 3: How often does your knowledge change?
If the information changes more than quarterly → RAG is almost certainly more practical than repeated retraining. If it's static and stable → fine-tuning can work.
Step 4: Do you need source attribution?
If yes → RAG. Fine-tuned models cannot cite sources.
Step 5: What is your volume and latency requirement?
If you need responses in under 500ms at millions of requests per day for a narrow, stable task → fine-tuning might be worth the investment. For most applications with moderate volume → RAG is simpler to operate.
| Question | Answer → RAG | Answer → Fine-tuning |
|---|---|---|
| Is the failure mode factual or knowledge-related? | Yes | No |
| Is the failure mode behavioural or style-related? | No | Yes |
| Does the knowledge change frequently? | Yes | No |
| Do you need source attribution? | Yes | No |
| Is the task highly specialised with stable patterns? | No | Yes |
| Is your budget for training constrained? | Yes | No |
| Do you need zero retrieval latency at high volume? | No | Yes |
| Do you want to use the latest frontier models? | Yes | No |
The hybrid approach: RAG + fine-tuning together
In 2026, hybrid systems are the practical default for production-grade quality. The RAG vs fine-tuning debate is mostly noise now. The real question is where to place knowledge, where to encode behavior, and how to evaluate both continuously.
The hybrid pattern works like this: fine-tune the model for consistent behaviour, style, and output format. Use RAG to supply current, verifiable factual knowledge. Each tool does its actual job.
[Fine-tuned model] — handles: output format, domain reasoning style, brand tone
+
[RAG layer] — handles: current facts, proprietary knowledge, source attribution
=
Production system with consistent behaviour AND up-to-date knowledge
A practical example: a financial services company builds a market analysis assistant. They fine-tune on internal analysis reports to internalise the company's analytical framework and output style — every response follows a specific structure, uses the company's terminology, and reasons in ways that match their analysts. They layer RAG on top to supply current market data, recent news, and proprietary research — knowledge that changes daily and can't be baked into model weights.
The fine-tuned model knows how to reason and how to format. The RAG layer knows what is true today. Neither alone does both jobs.
There is also a third approach worth knowing: RAFT (Retrieval-Augmented Fine-Tuning). RAFT fine-tunes a model on examples that include retrieved context — training the model to reason over retrieved documents in the way your application requires. It combines the benefits of both approaches at the cost of significant training data preparation.
The costs nobody quotes you upfront
The decision between RAG and fine-tuning is often framed as a technical choice. It's also a cost and operational choice — and the honest costs of fine-tuning are systematically underquoted in vendor conversations.
RAG costs:
- Embedding generation: ~$0.13/million tokens for text-embedding-3-small
- Vector database hosting: $50–300/month depending on scale (Pinecone, Weaviate)
- Inference: standard API costs, slightly higher per query due to larger context window with retrieved chunks
- Engineering time: chunking strategy, embedding pipeline, retrieval tuning
Fine-tuning costs:
- Data curation: often the largest cost — high-quality labelled examples are expensive to produce. Plan 500–1000 high-quality examples as a minimum for meaningful fine-tuning
- Training compute: LoRA on a 7B model costs ~$20–50 per run on cloud GPU; larger models scale up significantly
- Evaluation: building a rigorous evaluation framework is essential and time-consuming
- Ongoing maintenance: budget 3–5x the training cost for ongoing lifecycle ownership over the next 12 months. Adapter versioning, quarterly revalidation, retraining runs when data drifts — these are recurring costs, not one-time work
The comparison that surprises most teams: a RAG system with good retrieval quality can be fully operational in two to four weeks. A fine-tuning project with proper data curation, training, evaluation, and deployment infrastructure typically takes three to four months before it outperforms a well-implemented RAG system. That timeline difference has a real opportunity cost.
A practical starting point for each approach
Starting a RAG system today:
- Choose your knowledge base sources and export them to text/PDF
- Chunk the content (400–600 token chunks with 50-token overlap is a reasonable starting point)
- Embed each chunk using OpenAI's
text-embedding-3-smallor Cohere'sembed-v3 - Store in a vector database — pgvector if you're already on PostgreSQL, Pinecone or Qdrant for a dedicated vector store
- Build the retrieval function (semantic similarity search over embeddings)
- Wire up to your LLM API with a system prompt that instructs grounding in retrieved context
- Measure: are the right chunks being retrieved? Are responses accurate? Add re-ranking if retrieval quality is insufficient
Starting a fine-tuning project today:
- Define the failure mode precisely — what specific behaviour needs to change?
- Collect 500–1000 high-quality input/output examples that demonstrate the desired behaviour
- Evaluate your base model against these examples before training — establish a baseline
- Choose LoRA or QLoRA with Axolotl, HuggingFace PEFT, or your cloud provider's fine-tuning service (OpenAI, Together AI, Fireworks)
- Train with a small initial run to validate the pipeline before full training
- Evaluate rigorously — use LLM-as-judge for scale, with human review on 5–10% of outputs
- Deploy with an A/B test against the base model — measure real improvement against your baseline, not against your intuition
Frequently asked questions
What is RAG in simple terms? RAG (Retrieval-Augmented Generation) gives an AI model access to an external knowledge base at query time. Instead of relying only on what the model learned during training, the system searches a database of documents, retrieves the most relevant ones, and provides them to the model as context before generating a response. The model's parameters never change — only the information it sees at runtime changes.
What is fine-tuning and when should I use it? Fine-tuning updates a model's parameters by training it on a curated dataset. It changes how the model behaves — its style, format, and domain reasoning — not just what information it can access. Use fine-tuning when your failure mode is behavioural: wrong tone, inconsistent output format, poor adherence to a specific schema or classification taxonomy. Don't use it to inject factual knowledge that changes over time — that's what RAG is for.
Is RAG better than fine-tuning? Neither is universally better — they solve different problems. RAG is better for keeping a model's knowledge current, attributing sources, and working with frequently changing information. Fine-tuning is better for internalising stable domain patterns, changing output style and format, and improving consistency on narrow, high-volume tasks. In 2026, hybrid systems that use both are the production default for applications that need both accurate knowledge and consistent behaviour.
How much data do I need for fine-tuning? For LoRA fine-tuning, 500–1,000 high-quality examples is a reasonable minimum for meaningful improvement on a specific task. Low-quality data produces worse results than no fine-tuning at all — curation quality matters more than quantity. For instruction fine-tuning on a new capability, 5,000–50,000 examples are more typical. OpenAI's fine-tuning documentation provides task-specific guidance for their hosted fine-tuning service.
What is LoRA and why is it the recommended fine-tuning approach in 2026? LoRA (Low-Rank Adaptation) adds small trainable adapter layers to a frozen base model instead of updating all parameters. This reduces training compute by 10–100x, preserves the base model's general capabilities (avoiding catastrophic forgetting), and makes the adapter portable — you can switch base models by re-attaching the adapter. QLoRA extends LoRA by first quantising the base model to 4-bit precision, enabling fine-tuning of very large models on accessible hardware.
What is the difference between RAG and a vector database? A vector database (Pinecone, Weaviate, Qdrant, pgvector) is a component of a RAG system — it's where the embedded document chunks are stored and searched. RAG is the architectural pattern that combines a vector database (for retrieval) with a language model (for generation). The vector database handles the "find relevant content" step; RAG describes the full pipeline from user query to grounded response.
Can I use RAG and fine-tuning together? Yes — this is the recommended production approach for demanding applications. Fine-tune the model to internalise stable behaviours, output formats, and domain reasoning patterns. Layer RAG on top to supply current, verifiable knowledge. The fine-tuned model handles how to reason and respond; the RAG layer handles what is true right now. Each tool does its actual job without asking the other to compensate for its weaknesses.

Iria Fredrick Victor
Iria Fredrick Victor(aka Fredsazy) is a software developer, DevOps engineer, and entrepreneur. He writes about technology and business—drawing from his experience building systems, managing infrastructure, and shipping products. His work is guided by one question: "What actually works?" Instead of recycling news, Fredsazy tests tools, analyzes research, runs experiments, and shares the results—including the failures. His readers get actionable frameworks backed by real engineering experience, not theory.
Share this article:
Related posts
More from AI
May 22, 2026
1225 red flags every business must spot before buying AI software — covering demo manipulation, data privacy gaps, missing error handling, AI-washing, and lock-in contracts, with a 4-week vendor evaluation framework.

May 13, 2026
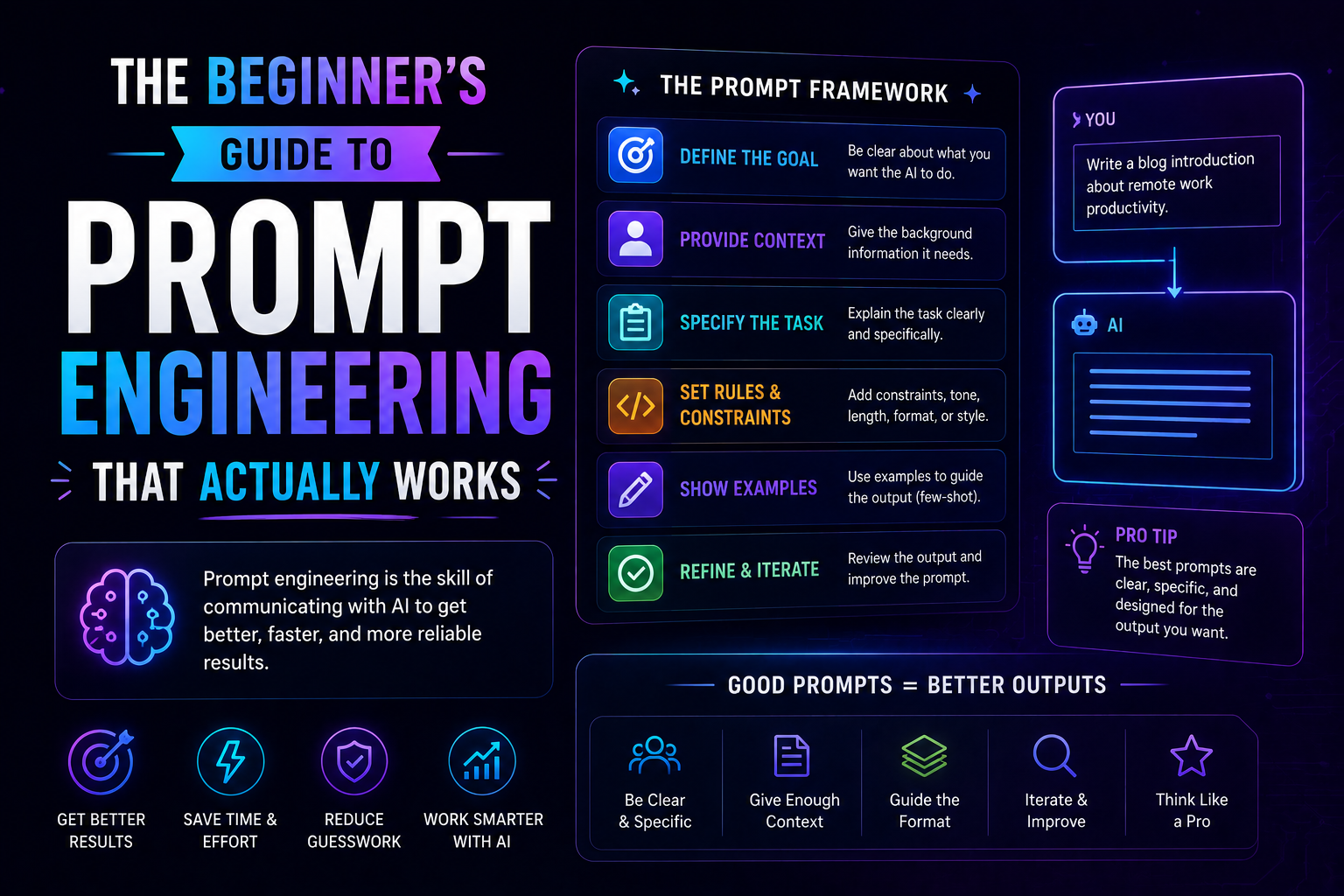
158The beginner's guide to prompt engineering that actually works in 2026 — covering the RCTF framework, chain of thought, few-shot examples, output contracts, and model-specific tips for Claude, GPT-5, and Gemini.
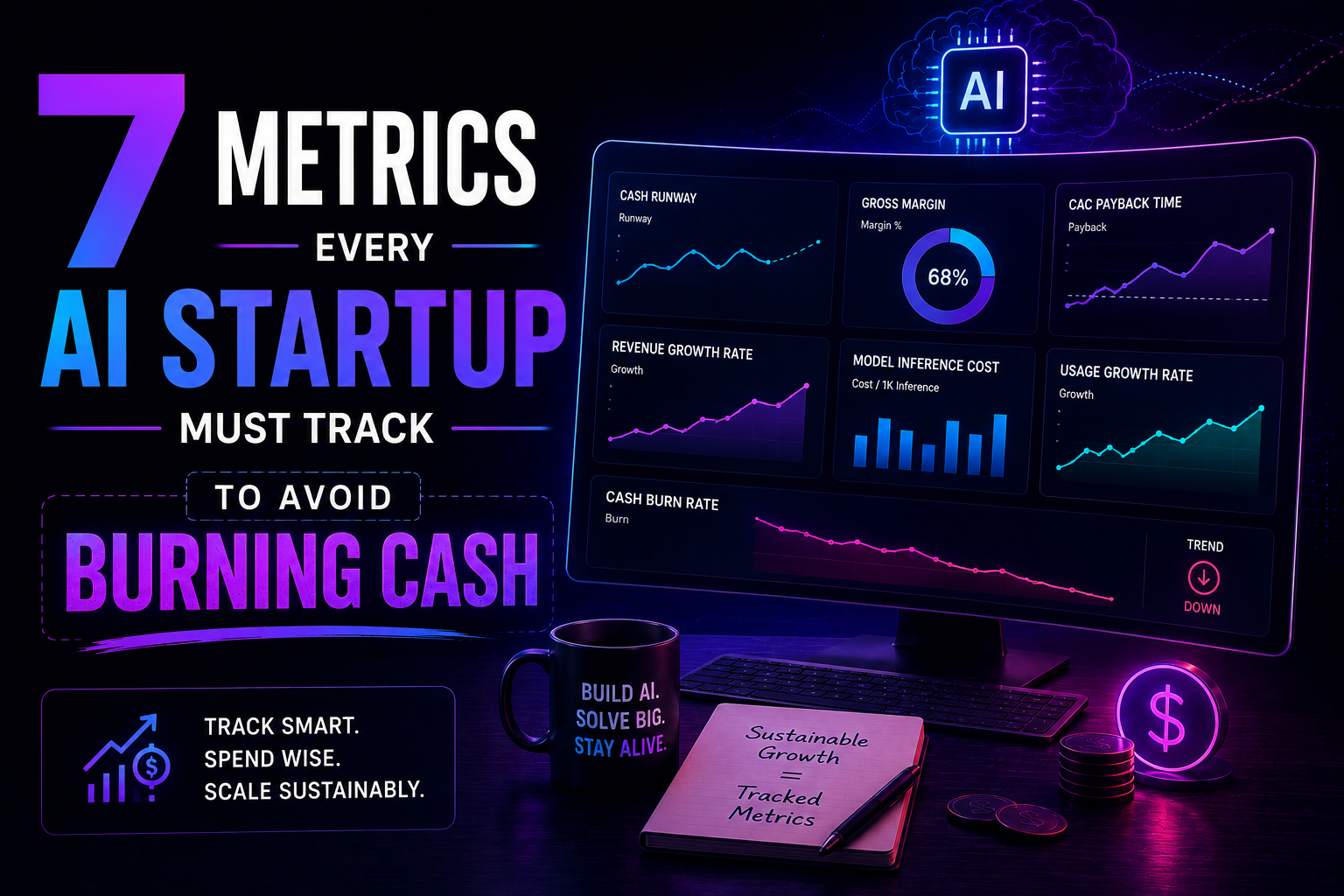
May 13, 2026
139Cost per inference. Gross margin per inference. Model downgrade tolerance. Most AI startups track SaaS metrics and miss the real numbers. Here are 7 that will save you from burning cash – with benchmarks and implementation steps.