How to evaluate LLMs for your production application
Not all LLMs are equal in production. Learn how to evaluate large language models for accuracy, speed, cost, safety, and fit — before you commit to one.

Introduction
Picking the wrong LLM for your production application is an expensive mistake — not just financially, but in developer time, user trust, and technical debt.
The problem is that most teams choose their AI model the wrong way. They read a benchmark leaderboard, pick the model at the top, and build around it. Then, three months later, they discover it hallucinates on their specific domain, costs ten times what they budgeted, or adds 4 seconds of latency to every request.
This guide walks you through a structured, repeatable framework for evaluating LLMs before you commit to one in production. Whether you are comparing Claude, GPT-4o, Gemini, Llama, or Mistral, these criteria apply across the board.
Why standard benchmarks are not enough
You have probably seen leaderboards like MMLU, HumanEval, or HELM. These are useful for a rough orientation, but they are not a substitute for evaluation on your actual use case.
Here is the core problem: a model that scores 90% on a general reasoning benchmark may score 60% on your specific task. Benchmarks measure average capability across diverse test sets. Your production application is not average — it is specific, with its own domain language, edge cases, user expectations, and failure modes.
What you need is not a model that scores well in general. You need a model that scores well on your data, your prompts, and your success criteria.
Step 1: Define your evaluation criteria first
Before you touch a single API, write down what "good" looks like for your application. This is the step most teams skip, and it costs them later.
Your criteria will typically fall into five categories:
Accuracy — Does the model produce correct, truthful answers for your domain? For a legal document tool, accuracy is non-negotiable. For a creative writing assistant, there is much more tolerance for variation.
Latency — How fast does the model need to respond? A customer-facing chatbot that takes 8 seconds to reply will hurt your conversion rate. A background document summarisation job can tolerate much more delay.
Cost — What is the cost per 1,000 tokens, and how does that multiply across your projected usage? A model that costs $15 per million tokens versus $1.50 per million tokens is a 10x difference — meaningful at scale.
Safety and reliability — How often does the model refuse reasonable requests, produce harmful outputs, or go off-script? This matters especially in regulated industries or when serving vulnerable user groups.
Context window and memory — Does the model support the context length your application needs? A contract analysis tool may need to process 100,000 tokens at once. A simple FAQ bot does not.
Write these criteria down and weight them. Not every criterion matters equally for your use case.
Step 2: Build a golden evaluation dataset
Your evaluation dataset is the foundation of everything. Without it, you are comparing models based on vibes — and vibes are not reproducible.
A good evaluation dataset contains:
- Representative inputs — Samples that reflect the actual distribution of requests your application will receive. Include common cases, edge cases, and adversarial inputs.
- Expected outputs — For each input, what does a correct response look like? This can be exact strings (for factual tasks), rubrics (for open-ended generation), or pass/fail tests (for code output).
- Failure examples — Include inputs where you already know the wrong answer, so you can test whether the model produces it.
Aim for a minimum of 100 examples for a rough evaluation. For production-grade confidence, you want 500 to 1,000 examples that cover your full input distribution.
Do not use the same dataset to prompt-engineer and evaluate. Use separate sets, or you will overfit your prompts to your test data and get a false sense of confidence.
Step 3: Evaluate accuracy on your domain
Run each candidate model through your golden dataset and measure how often it produces a correct output. How you measure correctness depends on your task type.
For factual or extractive tasks (e.g., "extract the payment terms from this contract"), you can use exact match or F1 score against the ground truth.
For generative tasks (e.g., "write a product description"), you need human raters or a model-as-judge approach — where a separate LLM (often GPT-4 or Claude) scores outputs against a rubric.
For code generation, run the generated code against a test suite. Pass rate is your metric.
One important pattern to watch: hallucination rate on your domain. Some models are more prone to making up citations, inventing statistics, or confabulating entity names. If your application is information-sensitive, measure this explicitly by including inputs where the correct answer is "I don't know" and checking whether the model says so.
Step 4: Benchmark latency under realistic conditions
Synthetic latency tests in a notebook are not the same as latency in production. Here is how to get realistic numbers.
Test with inputs that represent your p50, p90, and p99 prompt lengths — not just short inputs. Long prompts take longer to process, and your tail latency will affect real users.
Measure time to first token (TTFT) separately from total response time. For streaming applications, TTFT is what the user feels most. For batch jobs, total time matters more.
Test under load. A model that responds in 500ms when you send one request may respond in 3 seconds when you send 50 concurrent requests. Run load tests that approximate your expected peak traffic before you commit.
If latency is critical for your use case, also evaluate smaller, faster model variants alongside frontier models. A 7B or 13B parameter model running locally or on a dedicated GPU may deliver better latency than a frontier API at a fraction of the cost — if accuracy is acceptable.
Step 5: Model the cost at your production scale
LLM pricing is almost always listed per million tokens. The math looks deceptively simple until you multiply it across real usage.
Here is a simple formula to estimate monthly cost:
Monthly cost = (average input tokens + average output tokens) × requests per day × 30 × price per million tokens / 1,000,000
Work through this for each model you are evaluating. If you expect 50,000 requests per day with an average of 800 input tokens and 400 output tokens:
- Model A at $15/M tokens: ~$27,000/month
- Model B at $1.50/M tokens: ~$2,700/month
That is a $290,000 annual difference. It changes the business case entirely.
Also factor in caching. Many providers offer prompt caching for repeated context (such as a long system prompt used in every request). Caching can reduce costs by 60–90% in the right architectures — check whether your workflow is eligible.
Step 6: Test safety, refusals, and edge case behaviour
A model that refuses to answer legitimate questions is a production problem just as much as one that answers harmful questions.
Test your candidate models with:
- Borderline but legitimate inputs — Queries that touch on sensitive topics but are clearly appropriate in your context (e.g., a medical app asking about drug interactions). Measure refusal rate on legitimate inputs.
- Adversarial prompts — Attempts to jailbreak the model, extract the system prompt, or cause it to deviate from its intended behaviour. How robust is each model?
- Out-of-scope inputs — What happens when a user asks something your system was not designed for? Does the model gracefully redirect, or does it make something up?
Document the failure modes you observe. Different models have different personalities in their failures — some hallucinate confidently, others over-refuse, others go off-topic. Match the failure mode you can tolerate with the model that produces it least.
Step 7: Evaluate integration complexity
The best model in the world is still a problem if it is painful to integrate and maintain.
Consider the following practical factors:
API reliability and uptime — What is the provider's historical uptime? Do they have SLAs for enterprise use? Downtime in a production AI feature reflects directly on your product.
Rate limits — What are the requests-per-minute and tokens-per-minute limits? Do they match your traffic patterns? Can you increase them with a paid plan?
SDK and tooling quality — Is there a well-maintained SDK in your language? Are structured outputs (JSON mode, function calling) supported and reliable? Poor SDK quality creates ongoing maintenance burden.
Data privacy and compliance — Does the provider's data processing agreement meet your compliance requirements? Do they train on your inputs by default, and can you opt out? This is often a blocker for healthcare, finance, and legal applications.
Model stability — Does the provider promise that a specific model version will not change behaviour without notice? Model drift — where the same model ID produces different outputs over time — is a real operational risk.
Step 8: Run a time-boxed pilot in production
No amount of offline evaluation replaces real user feedback. Before committing fully to a model, run a controlled pilot.
Deploy the top one or two candidates to a small percentage of real traffic — 5% or 10% — and instrument everything. Track:
- User satisfaction signals (thumbs up/down, session continuation, task completion rate)
- Error rates and edge case hits
- Actual latency and cost against your projections
- Any safety or quality incidents
Run the pilot for two to four weeks. Patterns that appear in your offline evaluation will often confirm in production, but you will also discover issues you never anticipated — domain-specific quirks, unexpected user input patterns, and real-world latency behaviour under your infrastructure.
A quick comparison matrix to guide your decision
Not every application needs the same model. Here is a rough guide to help you match use cases to priorities:
| Use case | Top priority | Secondary priority |
|---|---|---|
| Customer-facing chatbot | Latency, safety | Accuracy |
| Document analysis | Accuracy, context window | Cost |
| Code generation | Accuracy, structured output | Latency |
| Content generation | Quality, cost | Safety |
| Internal tool / back-office | Cost, accuracy | Latency |
| Regulated industry app | Safety, compliance | Accuracy |
Use this as a starting point, not a prescription. Your specific constraints always take precedence.
Common mistakes to avoid
Choosing based on marketing. A model being described as "state of the art" on a vendor's homepage tells you nothing about its performance on your task. Always test.
Evaluating only on easy inputs. Frontier models all perform reasonably on well-formed, clear prompts. The differentiation shows up on ambiguous inputs, edge cases, and adversarial queries.
Ignoring total cost of ownership. API cost is visible. Engineering time to manage model drift, retries, and fallbacks is not. Add it to your calculations.
Picking a model and never re-evaluating. The LLM landscape moves fast. A model that was the best choice six months ago may have been surpassed — or the provider may have quietly updated it in ways that hurt your use case. Build re-evaluation into your quarterly engineering review.
Not version-locking your model calls. Always pin to a specific model version (e.g., claude-sonnet-4-20250514 rather than claude-sonnet-latest). This prevents silent behaviour changes from breaking your production system.
Conclusion
Choosing an LLM for production is an engineering decision, not a marketing one. The model with the best benchmark score, the biggest parameter count, or the most press coverage is not automatically the right choice for your application.
Follow the framework: define your criteria, build your evaluation dataset, measure accuracy on your domain, stress-test latency and cost at scale, and run a real-world pilot before committing.
Do this once properly and you will save yourself months of firefighting later.

Iria Fredrick Victor
Iria Fredrick Victor(aka Fredsazy) is a software developer, DevOps engineer, and entrepreneur. He writes about technology and business—drawing from his experience building systems, managing infrastructure, and shipping products. His work is guided by one question: "What actually works?" Instead of recycling news, Fredsazy tests tools, analyzes research, runs experiments, and shares the results—including the failures. His readers get actionable frameworks backed by real engineering experience, not theory.
Share this article:
Related posts
More from AI
May 27, 2026
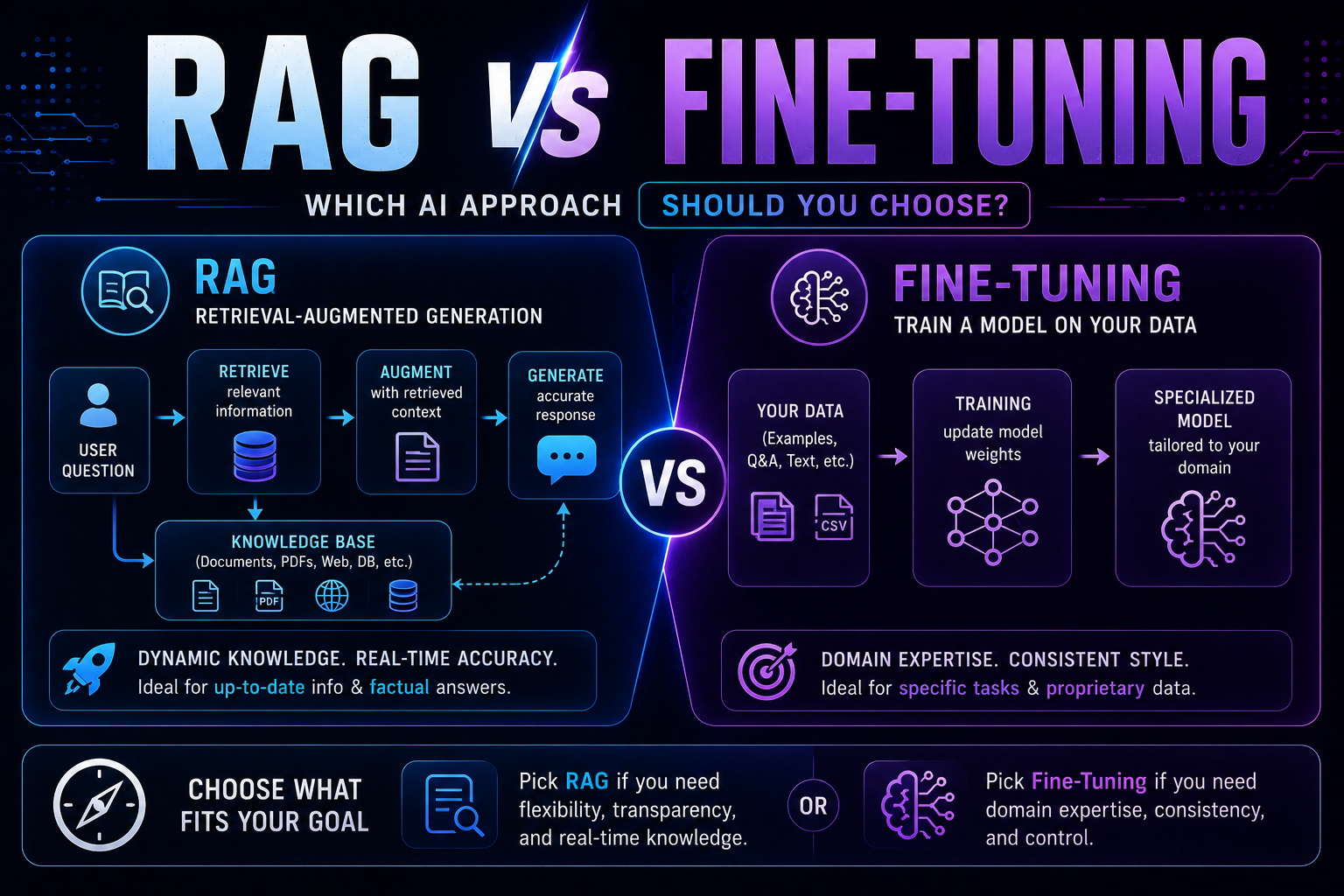
142RAG vs fine-tuning in 2026 — a practical guide covering when to use each, how both work with real code examples, the form vs facts distinction, hybrid approaches, true costs, and a decision framework to choose the right AI architecture for your use case.
May 22, 2026
1475 red flags every business must spot before buying AI software — covering demo manipulation, data privacy gaps, missing error handling, AI-washing, and lock-in contracts, with a 4-week vendor evaluation framework.

May 13, 2026
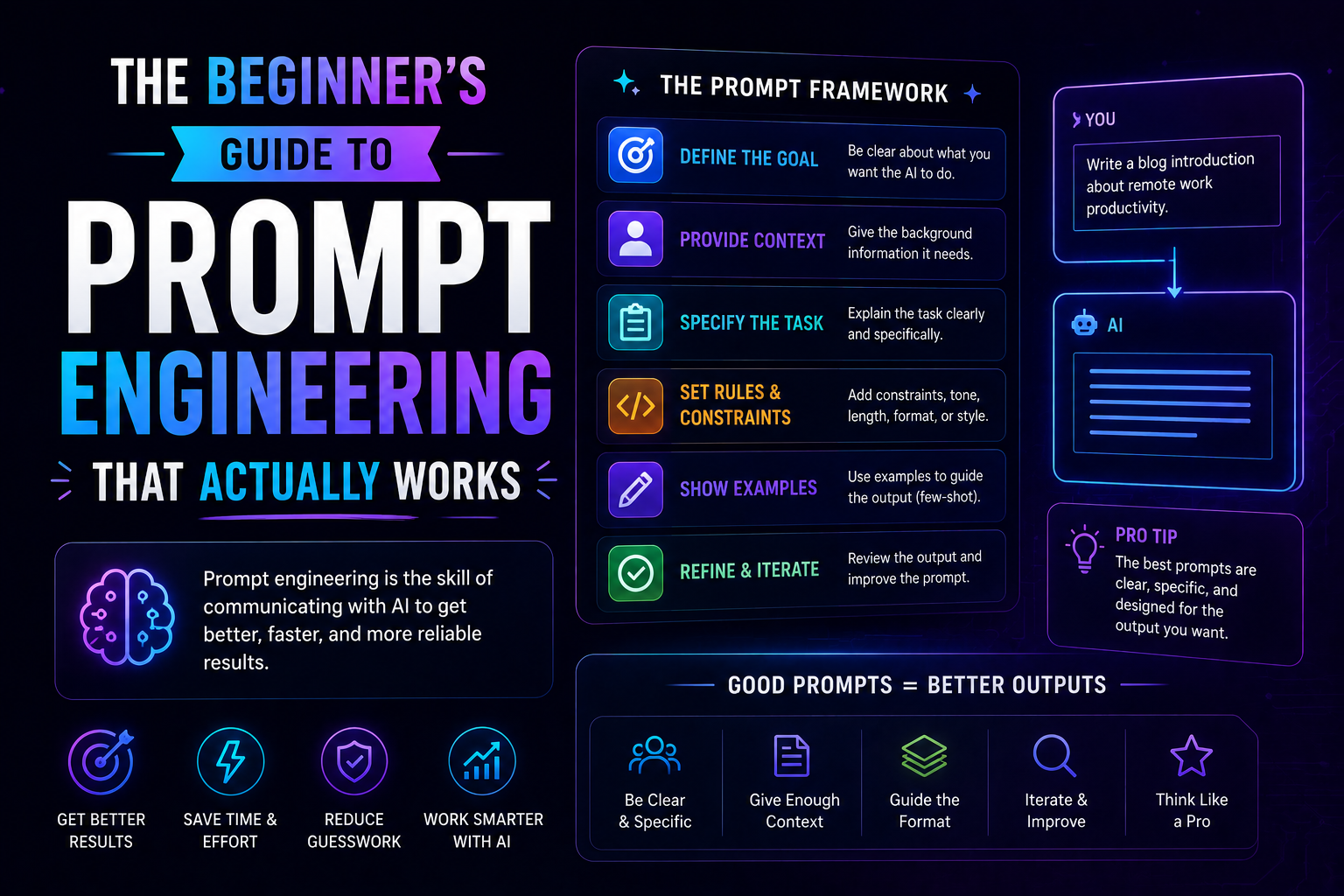
1026The beginner's guide to prompt engineering that actually works in 2026 — covering the RCTF framework, chain of thought, few-shot examples, output contracts, and model-specific tips for Claude, GPT-5, and Gemini.