7 Mistakes Companies Make When Building AI Features
80% of AI projects fail. Not because the technology is broken — because companies keep making the same predictable mistakes. Here's what they are and how to avoid them.

There's never been more pressure to ship AI features. Investors ask about it. Competitors are announcing it. Product managers are adding it to roadmaps. And yet, despite record levels of investment, the outcomes are frequently disappointing.
The numbers are stark. According to recent data, 80% of AI projects fail — double the failure rate of traditional IT initiatives. More than 50% of generative AI initiatives fail to meet their operational goals. Around 60% of companies see no significant return on their AI investment. And 42% of companies have now abandoned most of their AI initiatives, up from just 17% two years prior.
This isn't a technology problem. The models are good. The APIs are accessible. The tooling has matured. The failure rate is driven almost entirely by predictable strategic and operational mistakes — mistakes that companies keep repeating because they're rushing to ship AI features without understanding what makes them succeed.
This article covers the seven mistakes that show up most consistently, why they're so easy to fall into, and what to do differently.
Mistake 1: Building AI features no one asked for
The most common and most expensive AI mistake is building a feature that solves a problem your users don't actually have, or that they don't experience painfully enough to change their behaviour for.
The pressure to ship AI often overrides the discipline of product thinking. Teams add AI-powered summaries, AI-powered search, AI-powered recommendations — not because users are asking for them, but because AI is the thing to add right now. One case study documented a company's AI-powered version of its core product being "less intuitive and accurate than the human-curated version" — a direct result of building AI into a product without first asking whether users wanted or needed it there.
The fundamental question that must come before any AI feature decision is: what is the specific user problem this solves, and is it painful enough that users will change their behaviour to benefit from it?
If your answer is "it makes things faster" or "it feels modern," those are not strong enough reasons. Users switch behaviours for significant pain relief — time saved in large amounts, frustrating tasks eliminated, capabilities they genuinely couldn't achieve before. A feature that makes something marginally faster adds minimal value and often adds complexity and trust concerns on top.
What to do instead: Start with the user problem, not the AI capability. Interview users. Identify the workflows they find most frustrating or time-consuming. Then ask whether AI can solve that specific problem better than the alternatives — including doing nothing, building a simpler rule-based solution, or improving the existing non-AI experience.
Mistake 2: Treating a demo as a product
AI features are uniquely easy to demo impressively and uniquely hard to make reliable in production. A language model producing a stunning response in a demonstration is not the same as a system that handles thousands of real user inputs, edge cases, ambiguous queries, and unexpected prompts at scale — day after day, without degrading.
One practitioner described building 80% of an AI system in a week using AI assistants. The remaining 20% — integrations, multi-agent coordination, production hardening — took eight months and tripled the budget. The "last mile" is where complexity hides, and most AI demos never show it.
The gap between what impresses in a board presentation and what works reliably for real users is enormous. Teams fall in love with the demo and rush to ship it, skipping the rigorous testing, error handling, monitoring infrastructure, and fallback logic that production systems require. Then they're surprised when user feedback is negative, hallucinations slip through, or the system behaves inconsistently.
What to do instead: Define what "production grade" means before you start building. That includes: a test suite covering edge cases and adversarial inputs, a monitoring system that surfaces failures and unexpected outputs, fallback behaviour when the AI fails or produces low-confidence results, and a feedback loop that lets you identify and fix problems as they emerge. Build those things alongside the feature, not after it ships.
Mistake 3: Ignoring data quality and data readiness
AI is only as effective as the data it consumes. This is one of the most repeated truths in the field and one of the most consistently ignored in practice.
Companies approach AI initiatives assuming their data is ready, only to discover that it's siloed across systems that don't talk to each other, inconsistently formatted, missing critical fields, or simply wrong in ways nobody noticed because the old system worked around it. When AI encounters this data, it doesn't work around the problems — it learns from them or fails because of them. Garbage in, garbage out is not a cliché. It's a law.
In manufacturing contexts, inconsistent naming conventions, miscalibrated sensors, and missing metadata lead to AI systems that produce unreliable outputs or confident-sounding wrong answers. The same dynamic plays out in SaaS products where user data is incomplete, in e-commerce platforms where product catalogues are inconsistently structured, and in B2B tools where customer records are riddled with duplicates and gaps.
Companies that succeed with AI investment allocate 50–70% of their budget to data infrastructure, quality, and governance — before writing a single line of model code. Companies that fail treat data as a detail to sort out later.
What to do instead: Before committing to an AI feature, audit the data it will rely on. Ask: Is this data actually available? Is it consistent? Is it complete? Is it clean enough to train on or query against? If the answer is no to any of those questions, fix the data problem first. Data readiness is not a prerequisite you can skip — it's the foundation the entire AI feature rests on.
Mistake 4: Skipping AI-specific testing
Every engineering team knows they need to test their software. AI features break the testing assumptions that teams have built their practices around, and most teams don't adjust accordingly.
Traditional software is deterministic: the same input produces the same output every time. AI systems are probabilistic: the same input can produce different outputs, and some of those outputs will be wrong in ways that are hard to predict and hard to catch with conventional unit tests.
AI-specific testing challenges that teams consistently underestimate include:
- Hallucination detection — AI models can produce confident-sounding incorrect information. Standard functional tests won't catch this.
- Edge case coverage — real user inputs are messier, more ambiguous, and more varied than any test suite predicts
- Regression on model updates — when the underlying model is updated (by the vendor or internally), behaviour changes in ways that may be subtle and widespread
- Prompt injection — users can deliberately craft inputs to manipulate AI behaviour in unintended ways
- Evaluation at scale — performance in testing with 100 sample inputs often doesn't predict performance with 10,000 real ones
The pressure to achieve quick ROI on AI investment leads teams to rush AI applications into production with minimal testing — a quick check for obvious bugs and a once-over, but not the systematic coverage these systems require.
What to do instead: Build an evaluation framework specific to your AI feature before you ship. Define what "correct" looks like for your use case. Create a dataset of representative inputs — including adversarial examples and edge cases — and measure your system against it. Set up automated regression testing so that model updates trigger a full evaluation run. Accept that AI testing is an ongoing investment, not a one-time gate.
Mistake 5: No monitoring, no feedback loop in production
Most companies treat shipping as the finish line for an AI feature. In reality, for AI it's the starting line.
AI systems degrade in ways that traditional software doesn't. User behaviour changes. The world changes. The distribution of inputs shifts over time, moving away from what the system was tested on. Models can silently begin underperforming — producing worse outputs gradually — without any obvious system error to alert the team.
If you can't see how your AI behaves in production, you don't control it. Yet many teams ship AI features with no more monitoring than they'd apply to a standard CRUD endpoint — basic uptime checks and error rates, with no visibility into output quality.
The result is that problems accumulate quietly. Users lose trust. Some switch to competitors. Others just stop using the feature without telling anyone. By the time the team investigates, weeks or months of degraded performance have eroded confidence in the product.
What to do instead: Build monitoring for your AI feature from day one, not as an afterthought. Instrument output quality, not just system health. Collect user feedback signals — thumbs up/down, corrections, abandonment — and route them back to your evaluation pipeline. Set up alerts for statistical drift in output characteristics. Create a regular cadence for reviewing a sample of real outputs manually. Think of production monitoring as the primary way you learn how your AI feature is actually performing.
Mistake 6: Underestimating the true cost
AI features are expensive in ways that aren't always visible upfront. Teams budget for model API costs and sometimes for compute. They rarely budget fully for everything else.
The hidden costs of AI features that catch teams off guard:
Prompt engineering time — crafting, testing, and iterating on prompts to get reliable outputs is a skilled, time-consuming activity that is systematically underestimated before a project starts.
Evaluation infrastructure — building the tooling to measure whether your AI is performing correctly, at scale, requires significant engineering effort.
Monitoring and observability — AI-specific monitoring (as covered above) adds cost in both tooling and engineering time.
Edge case handling — every production AI feature has a long tail of edge cases that require careful handling. Discovering and fixing them takes time.
Ongoing model maintenance — when your model vendor updates the underlying model, or when you need to retrain on new data, there is real engineering cost involved.
Compute at scale — token costs that look trivial in development can become significant at production volume. One feature that hits millions of users behaves very differently on an API bill than the same feature in a demo.
A common pattern: a team builds 80% of an AI feature quickly and cheaply, then discovers that the final 20% — the part that makes it production-reliable — takes far longer and costs far more than the entire initial estimate.
What to do instead: Before committing to an AI feature, run a realistic cost model that includes prompt engineering, evaluation, monitoring, maintenance, and compute at your projected production scale. Build in a contingency for the edge case work you haven't discovered yet. Run a small paid pilot to calibrate actual costs before scaling. Cost visibility prevents the budget surprises that kill AI projects.
Mistake 7: Launching enterprise-wide before proving value in a small pilot
Organisations feel the urgency of AI adoption and respond by going big — launching AI initiatives across multiple business units, transforming multiple workflows simultaneously, spending months building infrastructure before delivering a single measurable outcome.
The average organisation scrapped 46% of AI proof-of-concepts before they reached production. Enterprise-wide rollouts compound risk dramatically. When one of many simultaneous AI initiatives hits a problem — bad data, a use case that doesn't actually work, user resistance — it becomes much harder to isolate, fix, and learn from. The complexity masks the signal.
The pattern that consistently fails: a company decides to implement AI across quality inspection, predictive analytics, customer support, and supply chain optimisation simultaneously. They spend 18 months building infrastructure. They never deliver a single measurable outcome. The budget gets cut. Internal scepticism about AI sets in and takes years to overcome.
This is what practitioners call "pilot purgatory" on the other end of the spectrum — not failing to start, but failing to finish, because the scope is too large to ship anything solid before momentum collapses.
What to do instead: Start with one narrow, high-pain use case that has a measurable outcome. Ship it. Measure it against a clear baseline. If it works, scale the pattern. If it doesn't, you've learned something cheaply and can pivot. The discipline is: no new AI pilots until one has shipped to production or been explicitly killed. The companies that build durable AI capabilities in 2026 are the ones that accumulate small, proven wins — not the ones that bet everything on a transformative initiative.
What the companies getting it right have in common
The patterns across successful AI feature builds are consistent:
They start with business outcomes, not technology. The question is never "what AI feature can we build?" It's "what user problem is painful enough to justify the cost and complexity of an AI solution?"
They treat data as a first-class investment. Data readiness, quality, and governance are not afterthoughts. They're the foundation. Successful teams spend more on data than on model costs.
They build for production from the start. Monitoring, evaluation, fallback handling, and feedback loops are planned before the first line of feature code, not added later if time permits.
They go narrow before they go broad. One use case, proven and measured, before scaling to the next. The compound effect of many small wins beats the organisational damage of one large failure.
They measure actual user outcomes, not adoption metrics. Getting users to click a button is not success. Reducing the time they spend on a painful task, or increasing the accuracy of a decision they make — those are success.
A checklist before shipping any AI feature
Run through this list before you commit to building:
| Question | Why it matters |
|---|---|
| What specific user problem does this solve? | Ensures you're building for real need, not AI for its own sake |
| How will we know if it's working in production? | Forces monitoring and evaluation to be planned upfront |
| Is the data it relies on clean, complete, and accessible? | Surfaces data readiness issues before they become blockers |
| What does "good output" look like, and how will we measure it? | Enables proper evaluation and regression testing |
| What happens when the AI produces a wrong or low-confidence answer? | Ensures fallback behaviour is designed, not an afterthought |
| What is the realistic total cost at production scale? | Prevents budget surprises that kill projects |
| Can we prove value with a small pilot before scaling? | Reduces risk and accelerates learning |
Final thoughts
The AI features that succeed in 2026 are not the most technically ambitious ones. They're the ones built to solve real problems for real users, with honest cost accounting, proper testing, production monitoring, and the discipline to start small and prove value before scaling.
The mistakes in this article are not exotic or hard to avoid. They're predictable, well-documented, and the reason the majority of AI projects still fail. The teams that avoid them are the ones that bring the same rigour to AI development that they'd apply to any other complex product decision — asking hard questions before they start building, not after they've already invested months in the wrong direction.
AI is a genuinely powerful tool for building better products. But the tool is only as good as the thinking behind how it's applied.
Frequently asked questions
Why do most AI features fail? Most AI feature failures are not technical. They stem from building features nobody asked for, underestimating data readiness requirements, skipping AI-specific testing, launching at enterprise scale without a proven pilot, and failing to monitor output quality in production. The technology is rarely the problem.
How should a company decide which AI feature to build first? Start with user research. Identify the workflow that is most painful, most frequent, and where AI can deliver a step-change improvement — not just a marginal one. The first AI feature should have a clear, measurable success metric and a small enough scope to ship, measure, and learn from within weeks rather than months.
What is "pilot purgatory" in AI development? Pilot purgatory describes the state where organisations have many AI experiments running simultaneously but none reaching production. It typically results from taking on too much scope before validating assumptions, or from the absence of a clear process for deciding which pilots advance, which get killed, and what "done" looks like.
How much should companies budget for AI feature testing and monitoring? There is no universal figure, but teams consistently underestimate it. Budget for evaluation infrastructure, prompt engineering iteration, edge case handling, and ongoing monitoring from the start — not as items to add if time permits. Some practitioners suggest allocating as much budget to testing and monitoring as to initial feature development.
What is the most important thing to get right before building an AI feature? Data quality and readiness. AI systems are only as good as the data they're trained on or querying against. Companies that invest in data infrastructure and governance before building AI features consistently outperform those that treat data as a detail to sort out later.
How do you measure the success of an AI feature? Define success before you build, not after you ship. Identify the specific user outcome you're trying to improve — time saved, error rate reduced, decisions improved — and measure it against a clear baseline. Adoption metrics (users who clicked the feature) are a weak proxy. Actual improvement in the user outcome you targeted is the real measure.

Iria Fredrick Victor
Iria Fredrick Victor(aka Fredsazy) is a software developer, DevOps engineer, and entrepreneur. He writes about technology and business—drawing from his experience building systems, managing infrastructure, and shipping products. His work is guided by one question: "What actually works?" Instead of recycling news, Fredsazy tests tools, analyzes research, runs experiments, and shares the results—including the failures. His readers get actionable frameworks backed by real engineering experience, not theory.
Share this article:
Related posts
More from AI
May 27, 2026
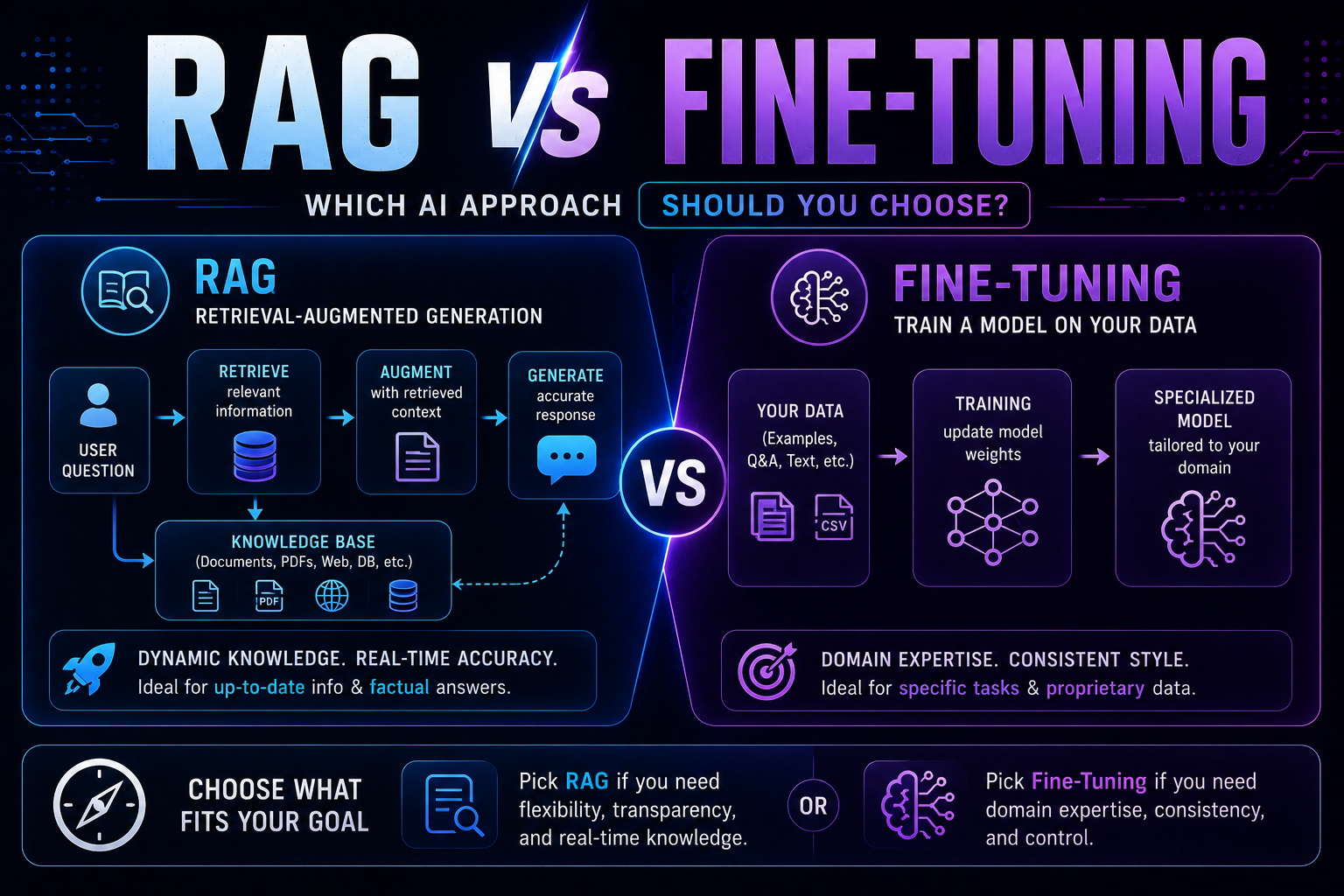
145RAG vs fine-tuning in 2026 — a practical guide covering when to use each, how both work with real code examples, the form vs facts distinction, hybrid approaches, true costs, and a decision framework to choose the right AI architecture for your use case.
May 22, 2026
1505 red flags every business must spot before buying AI software — covering demo manipulation, data privacy gaps, missing error handling, AI-washing, and lock-in contracts, with a 4-week vendor evaluation framework.

May 13, 2026
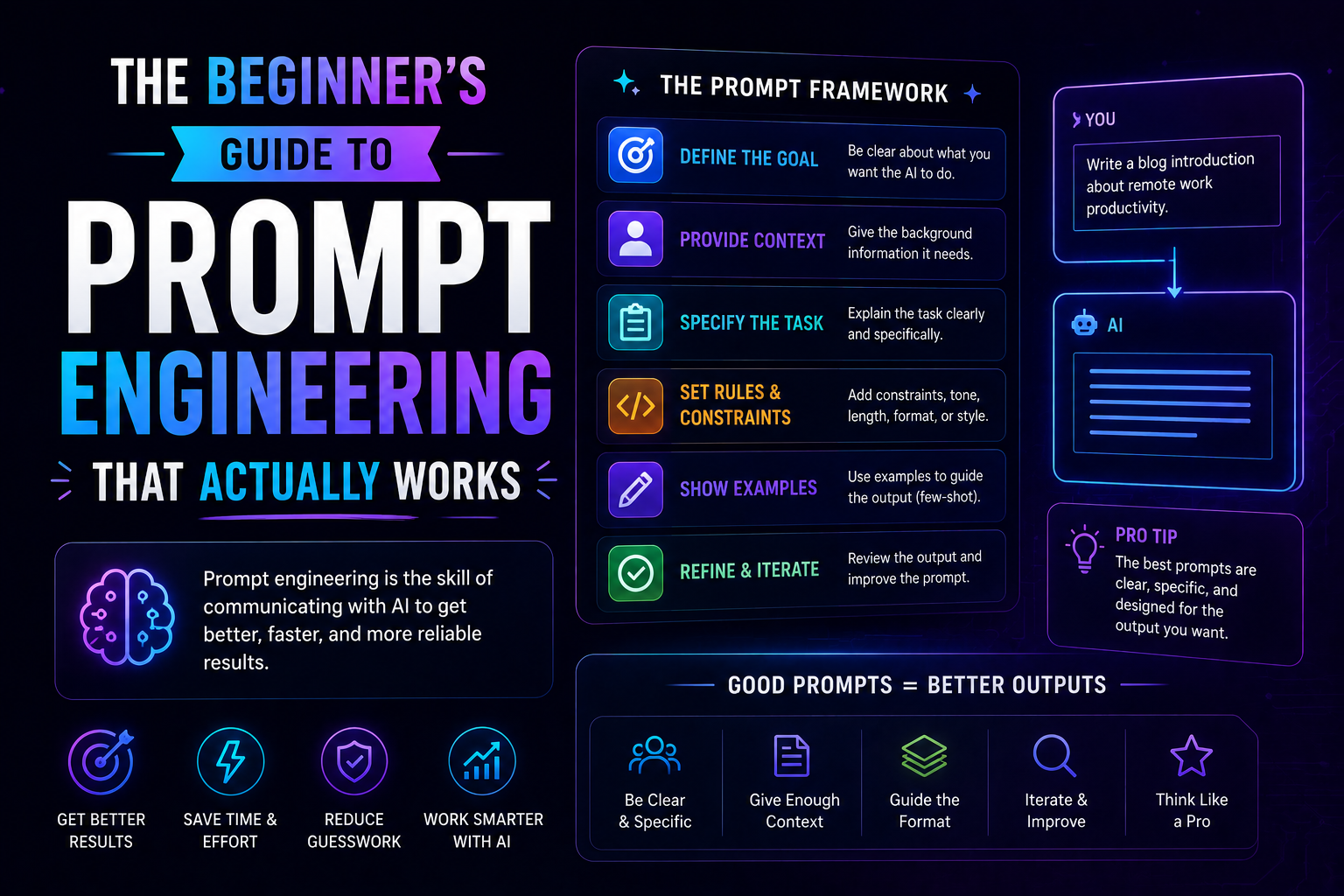
1036The beginner's guide to prompt engineering that actually works in 2026 — covering the RCTF framework, chain of thought, few-shot examples, output contracts, and model-specific tips for Claude, GPT-5, and Gemini.