The New Architectural Layer Nobody's Talking About
You've got models, tools, and orchestration. But you're missing the layer that catches silent failures before they become disasters. Here's the architecture change every AI team needs in 2026 — and why most vendors won't tell you about it.

Prompt engineering is old news. RAG is table stakes. Agentic workflows are everywhere. But there's a hidden layer — between the model and the user — that 90% of teams skip. It's not observability. It's not guardrails. It's something else entirely. This article names it, shows you why your agents are failing without it, and gives you a weekend-sized implementation plan.
Let me ask you something uncomfortable.
When your AI agent makes a mistake — not a crash, not an exception, but a confident wrong answer — how do you catch it?
Not after the user complains. Not in the logs three days later. I mean in the moment.
If you hesitated, you're not alone.
We've spent two years building better models, better prompts, better RAG pipelines. But we've ignored a whole layer of architecture. And it's quietly destroying reliability, trust, and budgets.
I call it the Verification Layer.
Nobody talks about it at conferences. No vendor sells it (yet). But every team that moves from demo to production ends up building it — usually after a very public failure.
Let me save you the pain.
The Gap That Keeps Me Up at Night
Here's what a typical AI agent stack looks like today:
User → Orchestration → Model → Tools → Response
Looks complete, right?
Now watch what happens in reality:
- User asks: "What's the return policy for the blue sweater I bought?"
- Agent searches memory. Finds nothing.
- Agent decides to guess instead of asking for clarification.
- Agent responds: "You have 30 days to return any item."
The real policy? 14 days. For sweaters? No returns on final sale.
The model was wrong. But the architecture had no way to know that. No verification. No second opinion. No cross-check.
This isn't a hallucination problem. This is an architectural blind spot.
What Most Teams Do (And Why It Fails)
I see three attempts at solving this. All of them miss the mark.
Attempt 1: "Better prompts"
You add "Please be accurate" to the system prompt. Cute. The model still guesses when it's uncertain because it's literally trained to complete patterns.
Attempt 2: "Observability tools"
You log every call. Great for debugging after the fact. Useless for stopping a bad response before it reaches the user.
Attempt 3: "Guardrails"
You block profanity, PII, and obvious jailbreaks. Important. But guardrails don't verify factual correctness. They don't catch the sweater policy error.
These are all necessary. None are sufficient.
You need a layer whose only job is: verify before you reply.
The Verification Layer Explained (With No Buzzwords)
The Verification Layer sits between your model's output and the user's eyeballs.
It's not a second model — though sometimes that helps. It's not a human-in-the-loop — though that's an option for high-stakes.
It's a lightweight, parallel system that asks one question:
"Does this response have permission to leave the building?"
Here's what it actually checks in real-time:
1. Source grounding – Did the model cite something? Can that citation be verified against the original document? If not, block.
2. Contradiction scan – Does this response conflict with any previous response in this conversation? I've seen agents tell a user "you're eligible for a refund" followed two turns later by "you're not eligible." The verification layer catches the flip.
3. Constraint validation – Did the user say "no jokes"? Did the compliance rule say "no financial advice"? The verification layer checks before the response goes out.
4. Confidence gating – If the model's internal confidence score (yes, most LLMs output this) is below a threshold, the layer blocks and triggers a fallback: ask for clarification, escalate to human, or admit uncertainty.
Most teams implement zero of these. The good ones implement one. The best implement all four.
A Real Example From a Production Failure
I consulted for a healthcare scheduling AI last quarter. The agent could book, reschedule, and cancel appointments. Worked beautifully in testing.
Then a patient asked: "Can I move my Tuesday appointment to Wednesday?"
The agent checked availability. Wednesday was full. So it booked Thursday instead. Without asking.
The patient showed up Thursday. The doctor was booked solid. Angry patient, angry doctor, angry manager.
Where was the verification layer?
It would have seen: "User asked for Wednesday. Response offers Thursday. Constraint 'exact day match' not satisfied. Block and clarify."
Instead, the agent was polite, confident, and catastrophically wrong.
We added three simple verification rules in one afternoon. No more unauthorized day changes.
Why Nobody's Talking About This (Yet)
Two reasons.
First, it's not sexy. Verification doesn't generate. It checks. VCs don't fund "the thing that says no." Startups sell generation, not verification. So the conversation stays focused on what models can do, not what they should be allowed to do.
Second, it's hard to measure. How do you track a disaster that didn't happen? You can't. So verification feels like overhead until the moment it saves you. Then it feels like a miracle.
But here's what I know: every team that's been burned by a confident wrong answer ends up building this layer. Quietly. Without a blog post. Without a vendor.
I'm writing this so you don't have to learn the hard way.
How to Build Yours This Weekend
You don't need a big budget. You need three things:
Step 1 – Pick one failure mode that scares you.
For most teams, it's confident wrong answers. For others, it's policy violations or contradictions. Pick one.
Step 2 – Write three verification rules in plain English.
Example:
- "If the response contains a date, verify it matches a date mentioned by the user."
- "If the response gives a refund amount, verify it matches the stored policy."
- "If the response says 'I'm sure,' check confidence score > 0.8."
Step 3 – Implement a lightweight checker.
A Python function that runs after the model generates but before the response is returned. If a rule fails, block and return a fallback: "I want to verify that before I answer. Let me check."
That's it. You've built the verification layer.
Over time, you'll add more rules, more checks, maybe a small LLM-as-judge. But start with three. You'll be ahead of 90% of teams.
The Brand Takeaway (How This Makes You Memorable)
Here's what I want people to say when they hear your name:
"They're the one who taught me that AI isn't about saying yes faster. It's about saying no reliably."
Anyone can build an agent that talks. The people who get noticed — who get quoted, who get consulted — build agents that verify before they speak.
That's your brand. Not the prompt wizard. Not the RAG expert. The person who understands that trust is the only moat that matters.
And trust doesn't come from better generation. It comes from better verification.
One last thing from me:
Go look at your most critical AI workflow right now. Find one response that would be catastrophic if it were wrong. Now imagine a verification layer catching it before the user sees it.
That's not architecture. That's peace of mind.
Build it this week. Thank me later.
Written by Iria Fredrick Victor who has seen too many confident wrong answers and decided to do something about it.

Iria Fredrick Victor
Iria Fredrick Victor(aka Fredsazy) is a software developer, DevOps engineer, and entrepreneur. He writes about technology and business—drawing from his experience building systems, managing infrastructure, and shipping products. His work is guided by one question: "What actually works?" Instead of recycling news, Fredsazy tests tools, analyzes research, runs experiments, and shares the results—including the failures. His readers get actionable frameworks backed by real engineering experience, not theory.
Share this article:
Related posts
More from AI
May 27, 2026
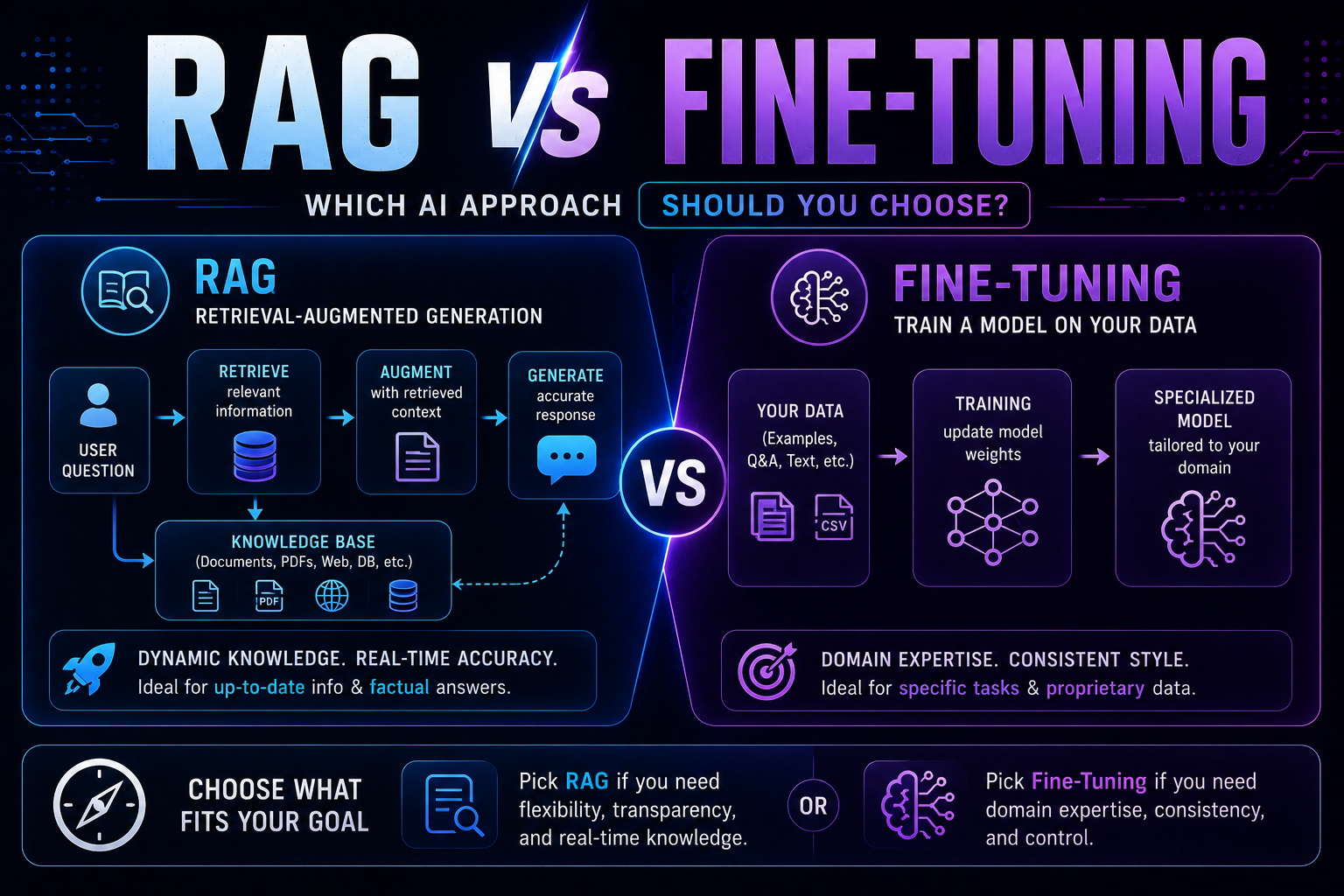
128RAG vs fine-tuning in 2026 — a practical guide covering when to use each, how both work with real code examples, the form vs facts distinction, hybrid approaches, true costs, and a decision framework to choose the right AI architecture for your use case.
May 22, 2026
1325 red flags every business must spot before buying AI software — covering demo manipulation, data privacy gaps, missing error handling, AI-washing, and lock-in contracts, with a 4-week vendor evaluation framework.

May 13, 2026
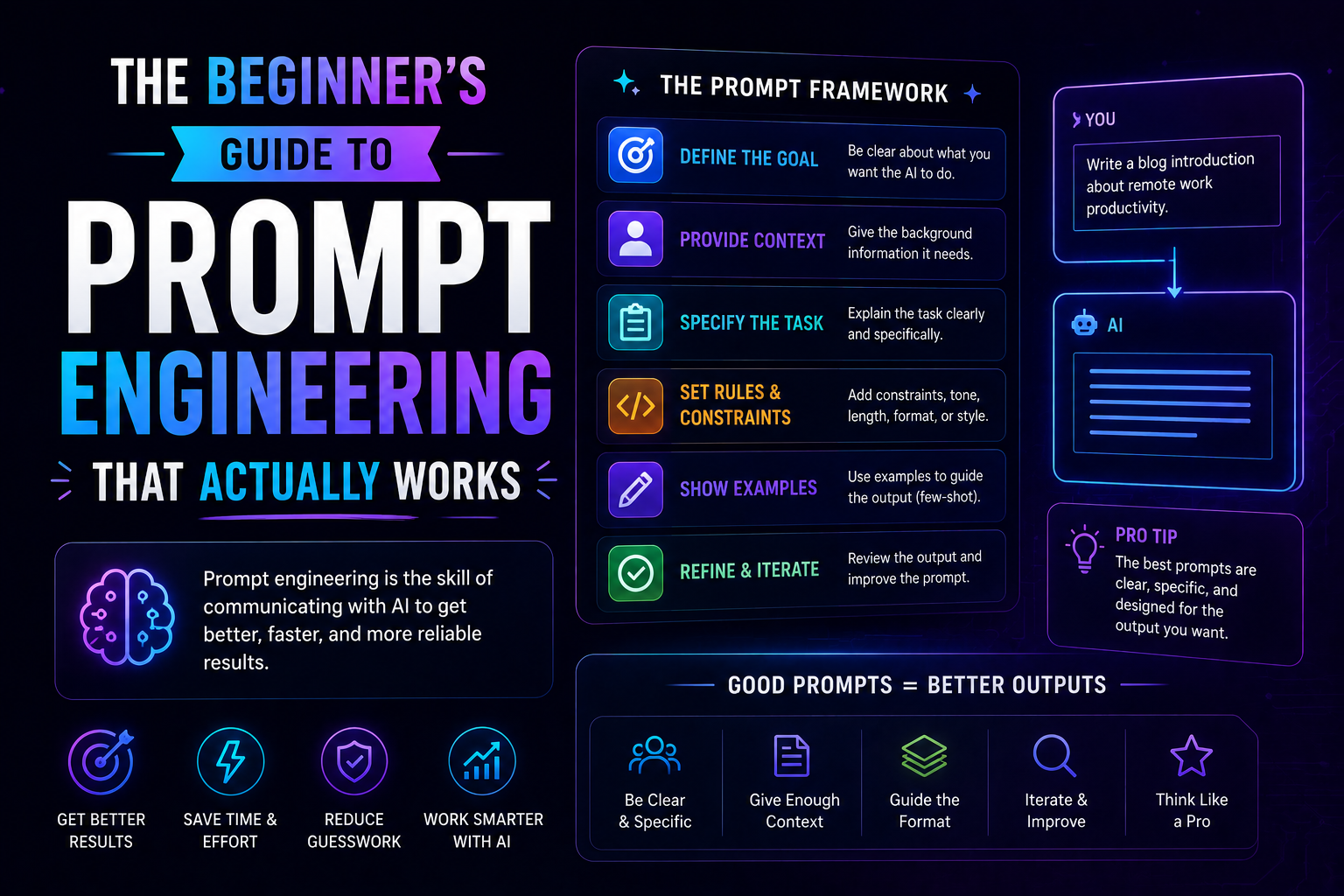
410The beginner's guide to prompt engineering that actually works in 2026 — covering the RCTF framework, chain of thought, few-shot examples, output contracts, and model-specific tips for Claude, GPT-5, and Gemini.