The "Human-in-the-Loop" Lie: Where You Still Need Actual People
"Human-in-the-loop" sounds responsible. Fredsazy explains why it's often a lie — and where you still genuinely need actual people.

Every AI vendor promises "humans in the loop." It sounds safe. Responsible. Like they've thought about the risks. But most of the time, that human is a ghost — overworked, under-trained, or completely absent. Here's the truth about where humans actually add value, where they're just theater, and how to build AI systems that respect human attention.
Let me tell you about the "human reviewer" who reviewed nothing.
I was auditing a company's AI-powered customer service system. They'd bought it from a vendor who promised "human review for all sensitive actions."
Impressive. Responsible. I asked to see the logs.
The system had flagged 12,000 "sensitive" actions in the past month. Each one supposedly reviewed by a human.
I looked at the review timestamps.
Action at 9:03:01. Human review at 9:03:02. Action at 9:03:05. Human review at 9:03:06. Action at 9:03:09. Human review at 9:03:10.
One second per review. Twelve thousand reviews. That human would have to work nonstop for over three hours — no breaks, no thinking time — to hit those timestamps.
They didn't. The "human reviewer" was clicking "approve all" as fast as the system would load.
Human-in-the-loop? More like human-in-the-sleep.
This happens everywhere. Vendors promise humans. Companies pay for humans. Then the humans are overworked, undertrained, or completely ignored.
Let me tell you where you still need actual people — and where "human-in-the-loop" is just a lie we tell ourselves.
The Three Lies of "Human-in-the-Loop"
Lie #1: "A human is reviewing everything."
No, they're not. They're skimming. They're clicking "approve all." They're watching Netflix while the auto-approver runs in the background.
One human cannot review thousands of AI decisions per day. It's not possible. The math doesn't work.
Lie #2: "The human will catch mistakes."
Only if they have context. Only if they have time. Only if they're paying attention.
Most human reviewers see a tiny slice of the conversation. They don't know what happened before. They don't know the customer's history. They don't know the business rules.
They're set up to fail.
Lie #3: "Human review adds safety."
If the human is tired, distracted, or under pressure, they add less safety than a well-designed automated system.
I've seen human reviewers approve catastrophic AI decisions because they weren't paying attention. The AI got blamed. But the human was the failure point.
Where You Still Actually Need Humans
Let me be clear: I'm not anti-human. I'm anti-lazy-human-washing.
Here's where real humans actually add value — and where no AI should operate without them.
1. High-stakes judgment calls
Anything involving significant money, safety, or legal liability.
- Approving a refund over $1,000
- Releasing medical information
- Making a hiring decision
- Authorizing a security exception
AI can recommend. AI can flag. AI can prepare. But a human makes the final call.
2. Edge cases the model wasn't trained on
Every AI has blind spots. Weird inputs. Unusual combinations. Things that never appeared in training data.
Humans are great at these. They can reason by analogy. Apply common sense. Make a reasonable guess.
Route unknown cases to humans. Let them handle the weird stuff. Use their decisions to retrain the model.
3. Customer-facing empathy
AI can simulate empathy. It can say "I understand your frustration."
It cannot feel frustration. It cannot genuinely apologize. It cannot build real trust.
For angry customers, grieving customers, confused customers — put a human in front. Not because AI can't handle the words. Because humans need to feel heard by another human.
4. Explaining decisions to stakeholders
"Why did the AI reject my loan?" "Why was my account suspended?" "Why was my refund denied?"
AI can produce an explanation. "Feature X had value Y, which crossed threshold Z."
That's not an explanation a human trusts. A human wants to talk to another human. To ask follow-ups. To feel like someone listened.
Humans explain to humans. AI explains to dashboards.
5. Training and improving the AI
Someone has to label data. Someone has to review failures. Someone has to decide what "correct" looks like.
That someone is a human. Not a prompt. Not a feedback loop. A person with judgment and context.
The best human-in-the-loop is the human before the loop — building, training, and maintaining the system.
Where "Human-in-the-Loop" Is Just Theater
Now for the uncomfortable part. Most human review is performative.
Low-stakes, high-volume tasks: If each decision is cheap and reversible, humans don't add value. They add cost and delay.
Example: Moderating "is this comment profane?" A human reviewer costs $0.05 per review. AI costs $0.001. Accuracy is similar. Let the AI run.
Tasks humans can't keep up with: If the AI processes 10,000 requests per hour, humans cannot review even 1% of them. The "human review" checkbox is a lie.
Tasks with no clear right answer: If even humans disagree, what is the human reviewer supposed to do? Flip a coin? The "human in the loop" doesn't resolve ambiguity. It just adds a second opinion with no more authority than the first.
A Real Example I Watched
A company had an AI that flagged potentially fraudulent transactions. "Human review required for any flag," they said.
The AI flagged 500 transactions per day. The fraud team had three people.
Each review took about 3 minutes if done properly. That's 25 hours of work per day. For three people.
What actually happened: The fraud team spent 10 seconds per review. "Looks fine." Click. Next. They approved 99% of flagged transactions without real scrutiny.
The human review was theater. It satisfied a compliance checkbox. It caught nothing.
When I asked them to change the process — review only the top 50 riskiest transactions per day, properly — they caught 4x more fraud with less work.
Lesson: Fewer, better human reviews beat more, worse human reviews.
How to Design Real Human-in-the-Loop (Not Theater)
If you actually want humans to add value, design for human attention.
Rule 1 – Don't ask humans to review everything
AI handles volume. Humans handle exceptions. Review only:
- High-stakes decisions
- Low-confidence predictions
- Edge cases the AI can't classify
Rule 2 – Give humans time
One human cannot review 500 decisions per hour. That's one decision every 7 seconds. Impossible to do well.
Cap human review volume. 20-30 per hour max. That's 2-3 minutes per review. Enough to actually think.
Rule 3 – Give humans context
Don't show them just the decision. Show them the conversation. The customer history. The relevant policies.
Humans need information to make good judgments. Starving them of context guarantees bad outcomes.
Rule 4 – Make it easy to say "let AI handle this"
Humans should only review things that actually need human judgment.
Provide a "trust AI" button. Let the human skip review for obvious cases. Reserve attention for the hard ones.
Rule 5 – Measure human performance
Are your human reviewers accurate? Consistent? Are they catching things the AI missed?
If you're not measuring human review quality, you have no idea if it's working.
The "Human-in-the-Loop" Maturity Model
Let me give you a framework to assess where you are.
| Level | Description | Reality |
|---|---|---|
| Level 1 | "Humans review everything" | Theater. Impossible at scale. |
| Level 2 | "Humans review high-risk cases" | Better. Still might be too many. |
| Level 3 | "Humans review low-confidence and high-risk cases" | Actually workable. |
| Level 4 | "Humans review exceptions, AI handles the rest, and humans have time/context" | Real human-in-the-loop. |
| Level 5 | "Humans train and improve the AI, plus handle rare exceptions" | The goal. |
Most teams claiming human-in-the-loop are at Level 1 or 2. They're lying to themselves.
Get to Level 4 or 5. That's where humans actually add value.
The Cost of Fake Human-in-the-Loop
Let me name what this lie costs you.
Burned-out humans: Reviewing thousands of AI decisions per day is exhausting. Your best people will leave.
Missed exceptions: When humans are overwhelmed, they miss the important cases. The fraud that slips through. The edge case that becomes a disaster.
False confidence: You think a human is watching. They're not. You build systems assuming a safety net that doesn't exist.
Compliance risk: If a regulator asks to see your human review logs, and they show 1-second reviews, you have a problem.
Fake human-in-the-loop is worse than no human-in-the-loop. At least with no human, you know you need other safeguards.
The Brand Takeaway
Here's what Fredsazy wants AI builders to remember:
"They don't lie about humans. They design for real human attention."
"Human-in-the-loop" has become a marketing phrase. A checkbox. A way to sound responsible without being responsible.
Real human review requires time, context, and reasonable volume. Anything else is theater.
Don't build theater. Build systems where humans genuinely add value — on the hard cases, the high-stakes decisions, the things AI can't handle.
That's not human-in-the-loop. That's human-where-it-matters.
One Last Thing
Look at your "human-in-the-loop" process right now.
How many reviews per human per hour? Do they have time to actually think? Do they have the context they need?
If the answer makes you uncomfortable, you're not alone. Most teams are in the same place.
But you can fix it. Reduce the volume. Add context. Measure quality.
Or stop pretending. Remove the fake human review and build better automated safeguards.
Both are better than the lie.
Written by Fredsazy — because humans deserve better than being theater.

Iria Fredrick Victor
Iria Fredrick Victor(aka Fredsazy) is a software developer, DevOps engineer, and entrepreneur. He writes about technology and business—drawing from his experience building systems, managing infrastructure, and shipping products. His work is guided by one question: "What actually works?" Instead of recycling news, Fredsazy tests tools, analyzes research, runs experiments, and shares the results—including the failures. His readers get actionable frameworks backed by real engineering experience, not theory.
Share this article:
Related posts
More from AI
May 27, 2026
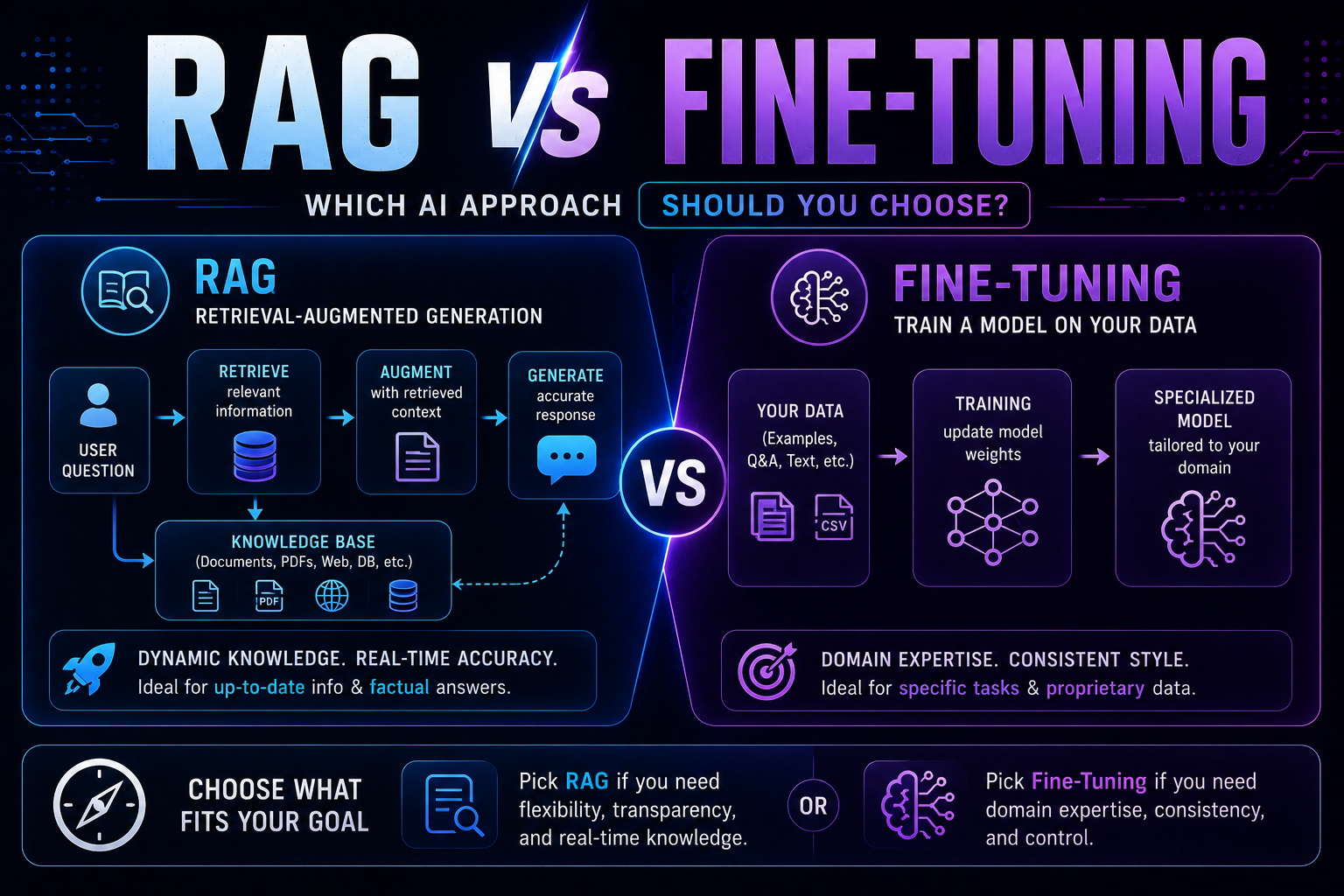
139RAG vs fine-tuning in 2026 — a practical guide covering when to use each, how both work with real code examples, the form vs facts distinction, hybrid approaches, true costs, and a decision framework to choose the right AI architecture for your use case.
May 22, 2026
1465 red flags every business must spot before buying AI software — covering demo manipulation, data privacy gaps, missing error handling, AI-washing, and lock-in contracts, with a 4-week vendor evaluation framework.

May 13, 2026
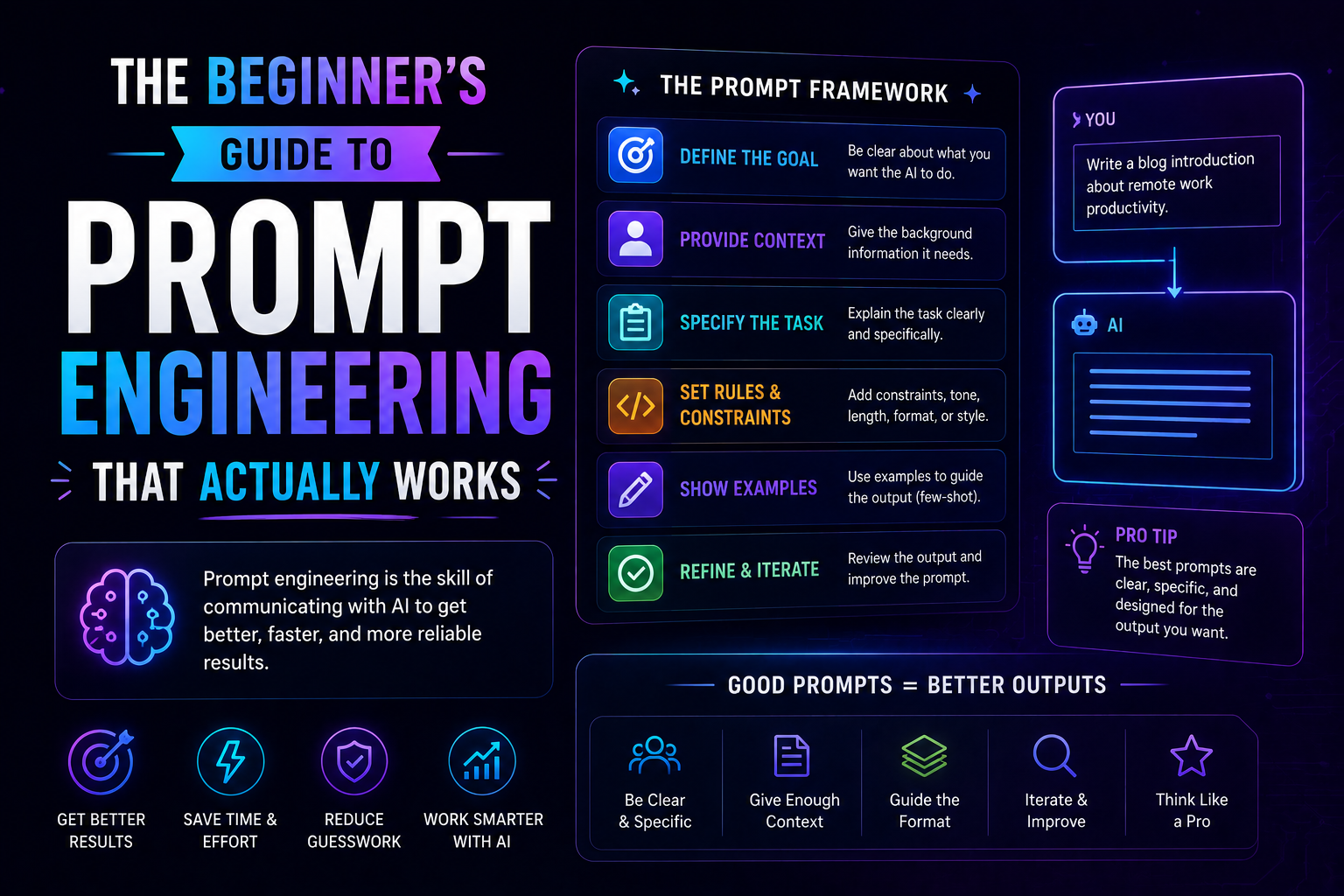
1021The beginner's guide to prompt engineering that actually works in 2026 — covering the RCTF framework, chain of thought, few-shot examples, output contracts, and model-specific tips for Claude, GPT-5, and Gemini.