The Self-Healing Pipeline: 73% of Enterprises Now Use AIOps to Beat Alert Fatigue
Your team is drowning in alerts. Fredsazy breaks down why 73% of enterprises are turning to AIOps — and what "self-healing" actually means in practice.

PagerDuty at 3 AM. Slack channels full of automated notifications. Email digests nobody reads. Alert fatigue isn't a meme — it's a crisis. That's why nearly three-quarters of enterprises have quietly adopted AIOps. Not for the hype. To stop the noise. Here's what self-healing pipelines actually look like, where they work, and where they still need humans.
Let me start with a number that explains everything.
73 percent.
That's how many enterprises are now using AIOps according to recent industry surveys. Not startups. Not hobbyists. Real companies with real infrastructure.
Why? Because their teams were drowning.
I've watched on-call engineers get woken up 40 times in a single night. Forty times. For things like "CPU usage spiked for 30 seconds" and "disk space is at 85%" and "a test job failed — no user impact."
Each alert was technically correct. Each alert was also useless. The engineer couldn't fix anything because nothing was actually broken. Just noisy.
That's alert fatigue. And it's why AIOps is spreading so fast.
What Is AIOps? (No Buzzwords, Just Reality)
Let me strip away the marketing.
AIOps stands for Artificial Intelligence for IT Operations. Fancy name. Simple idea: use AI to handle the boring, repetitive, noisy parts of keeping systems running.
That means:
- Alert filtering – The AI learns which alerts actually matter and silences the rest
- Root cause analysis – Instead of 50 alerts for one problem, the AI says "it's the database again"
- Automated remediation – The AI fixes common problems without waking a human
- Prediction – The AI spots issues before they become incidents
The goal isn't to replace humans. It's to make sure humans only get involved when they're actually needed.
For the 73% of enterprises using AIOps, that's not a nice-to-have. It's the only way to keep their teams from burning out.
The Alert Fatigue Crisis (Explained Simply)
Let me make sure you feel the problem.
A typical medium-sized company might have:
- 50 microservices
- 10,000 metrics being tracked
- 500 alert rules configured
- 200 alerts per day
Two hundred. Every day. Most of them false, duplicate, or low-priority.
What happens to the on-call engineer?
Week one: They check every alert. Exhausting. Week two: They start skimming. Dangerous. Week three: They ignore most alerts. Inevitable. Week four: They miss the one alert that actually mattered. Disaster.
That's alert fatigue. It's not a training problem. It's not a discipline problem. It's a volume problem.
Humans cannot process 200 alerts per day and stay sharp. We're not built for it.
AIOps is the answer not because AI is smarter, but because AI doesn't get tired.
How Self-Healing Actually Works
Let me walk you through a real example.
Without AIOps:
- Database connection pool fills up
- First timeout alert fires
- Second timeout alert fires
- "Database slow" alert fires
- "API latency increased" alert fires
- "User login failures" alert fires
- On-call engineer wakes up
- Engineer reads 15 alerts, traces to database, increases connection limit
- Total time: 25 minutes of engineer attention
- Engineer can't fall back asleep
With AIOps (self-healing pipeline):
- Database connection pool fills up
- AI sees the pattern (connection count rising, timeouts starting)
- AI checks: has this happened before? Yes, three times last month
- AI knows the fix: increase connection limit by 50%
- AI runs the fix automatically
- AI sends one summary alert: "Database connection pool filled up. Auto-resolved by increasing limit. No action needed."
- Engineer sleeps through the night
Same problem. Completely different outcome.
The engineer never touched it. The system healed itself. The engineer stayed asleep.
That's the promise of AIOps. And for 73% of enterprises, it's already real.
Where Self-Healing Works (And Where It Doesn't)
Let me be clear about the boundaries.
Works well:
- Known problems with known fixes (restart a service, increase a limit, clear a cache)
- High-frequency issues (the same alert firing over and over)
- Problems with clear metrics (CPU, memory, disk, network)
- Non-critical systems (internal tools, batch jobs, reporting)
Doesn't work well:
- Novel problems (never seen before, no pattern to match)
- Problems requiring business judgment (should we fail over? will customers notice?)
- Problems with ambiguous data (logs say "error" but no root cause)
- Critical systems (can't risk an AI making the wrong call)
The best AIOps implementations know these boundaries. They automate the obvious stuff. They escalate the uncertain stuff. They learn from both.
A Real Example I Watched
I was talking with someone on an infrastructure team at a mid-sized company. They'd been drowning in alerts. Hundreds per week. Their on-call engineers were burning out and quitting.
They implemented a simple AIOps filter. Nothing fancy. Just a tool that learned which alerts were correlated and which were usually false.
The first week, their alert volume dropped 60 percent.
Engineers started sleeping through the night. Response times to real incidents actually improved because they weren't exhausted from chasing false alarms.
The second week, they added automated remediation for the top three repetitive issues. Restart the logging agent when it stops. Clear the temp directory when it fills up. Recycle the connection pool when it hits 90 percent.
Another 30 percent of alerts disappeared.
In one month, they went from "on-call is destroying our team" to "on-call is annoying sometimes but manageable."
No new engineers hired. No massive budget. Just AIOps applied thoughtfully.
The Numbers That Matter
Let me give you some numbers I've seen consistently across teams using AIOps.
Alert volume reduction: 50-80 percent. The AI filters out the noise. Humans only see what matters.
Mean time to detection (MTTD): Down 40-60 percent. The AI spots patterns faster than humans scanning dashboards.
Mean time to resolution (MTTR): Down 30-50 percent for known issues. The AI runs fixes instantly instead of waiting for a human.
Engineer satisfaction: Up significantly. People stop dreading on-call. Retention improves.
These aren't theoretical. They're happening in production right now.
What the 27% Are Missing
Let me talk about the other 27% — the enterprises not using AIOps.
Some are waiting for the technology to mature. Fair enough.
But many are stuck on objections that don't hold up.
"We can't trust AI to fix things automatically."
You don't have to. Start with alert filtering only. Let the AI recommend fixes without running them. Have a human approve. That's still AIOps. Just slower.
"Our environment is too unique."
Every environment is unique. AIOps tools learn your patterns. They don't come with pre-set rules. They adapt.
"We don't have the data."
You have logs. You have metrics. You have alerts. That's the data. AIOps works with what you already have.
"It's too expensive."
Not compared to losing your best engineers to burnout. Not compared to missing a critical incident because everyone was ignoring alerts.
The 73% have done the math. It works.
How to Start (Without Breaking Everything)
Here's a safe, boring, effective path.
Step 1 – Measure your current alert volume
How many alerts per day? How many are actionable? How many are duplicates? You need a baseline.
Step 2 – Pick the noisiest alert
Find the alert that fires most often but rarely matters. Configure AIOps to silence it unless something changes.
Step 3 – Add correlation
Instead of 10 alerts for the same root cause, make AIOps group them into one. Your engineers will notice the difference immediately.
Step 4 – Automate one fix
Pick a problem that happens weekly and has a clear fix. Have AIOps run that fix automatically. Watch for a month. If it works, add another.
That's it. No giant rewrite. No expensive consultant. Just steady, measurable progress.
The Brand Takeaway
Here's what I want people to think when they hear Fredsazy talk about AIOps:
"They don't sell the hype. They explain what actually works — and what doesn't."
Anyone can say "AI will fix your alerts." The people who get noticed — who get trusted with real infrastructure — are the ones who know where self-healing works, where it fails, and how to start small.
Alert fatigue is real. It burns out good engineers. It makes teams miss real problems.
AIOps isn't magic. But for 73% of enterprises, it's the only thing keeping the lights on without losing their minds.
One Last Thing
Look at your own alert volume right now.
How many alerts did your team get yesterday? Last week? Last month?
Now ask yourself: how many of those actually required a human?
The answer is probably less than half. Maybe less than 20 percent.
That's your opportunity. Not to replace your team. To let them focus on what matters.
Start with one noisy alert. Silence it. See what happens.
You might finally get some sleep.
Written by Fredsazy — because 200 alerts per day is not a sustainable lifestyle.

Iria Fredrick Victor
Iria Fredrick Victor(aka Fredsazy) is a software developer, DevOps engineer, and entrepreneur. He writes about technology and business—drawing from his experience building systems, managing infrastructure, and shipping products. His work is guided by one question: "What actually works?" Instead of recycling news, Fredsazy tests tools, analyzes research, runs experiments, and shares the results—including the failures. His readers get actionable frameworks backed by real engineering experience, not theory.
Share this article:
Related posts
More from Devops
May 27, 2026
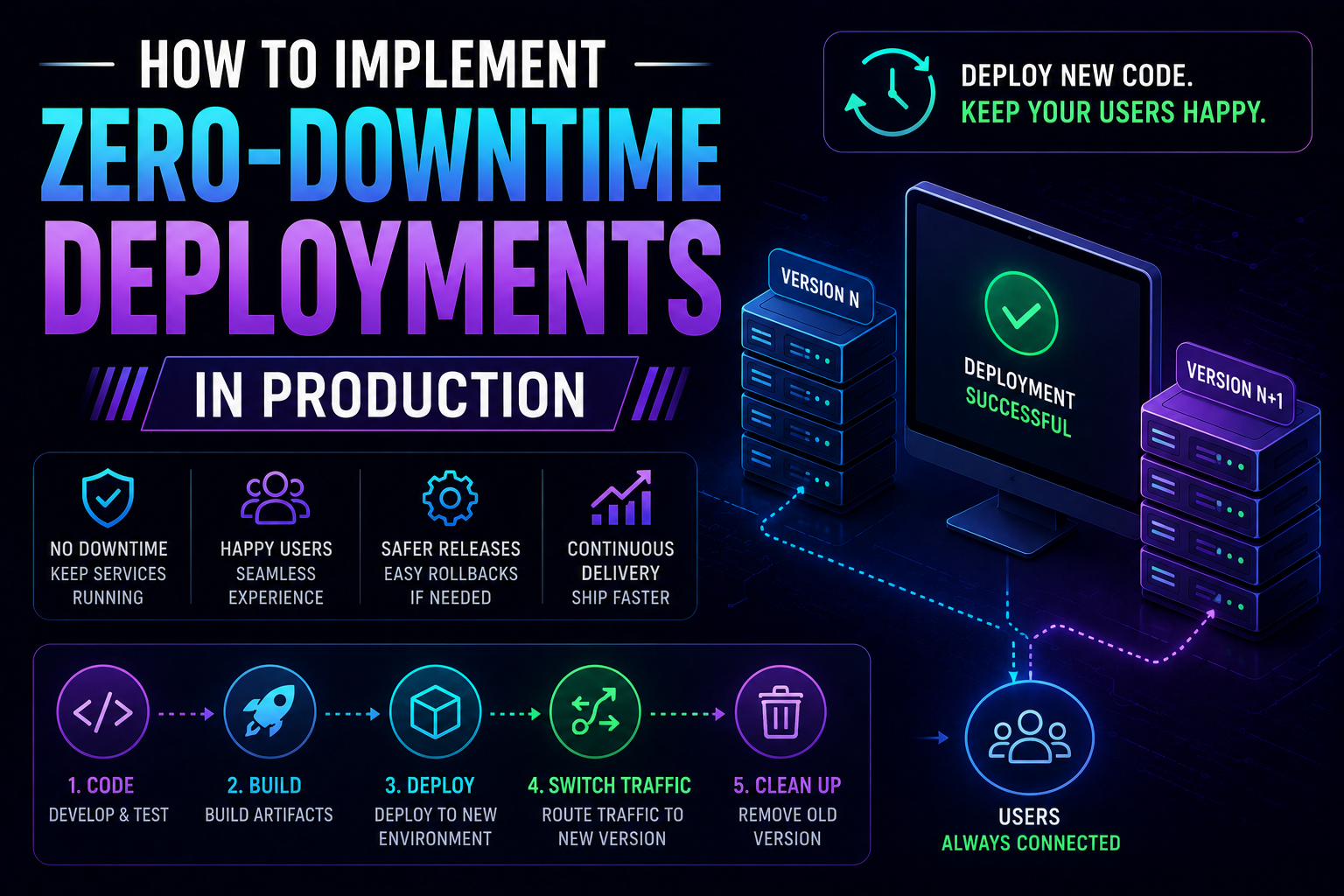
195Learn how to implement zero-downtime deployments in production — covering rolling updates, blue-green deployments, canary releases, feature flags, database migration patterns, graceful shutdown, and automated rollback with real Kubernetes YAML and code examples.
May 13, 2026
894AWS vs Azure vs GCP in 2026 — an honest, vendor-neutral comparison covering market share, AI/ML tooling, pricing, Kubernetes, compliance, and which cloud platform suits your team's specific workload and ecosystem.

May 13, 2026
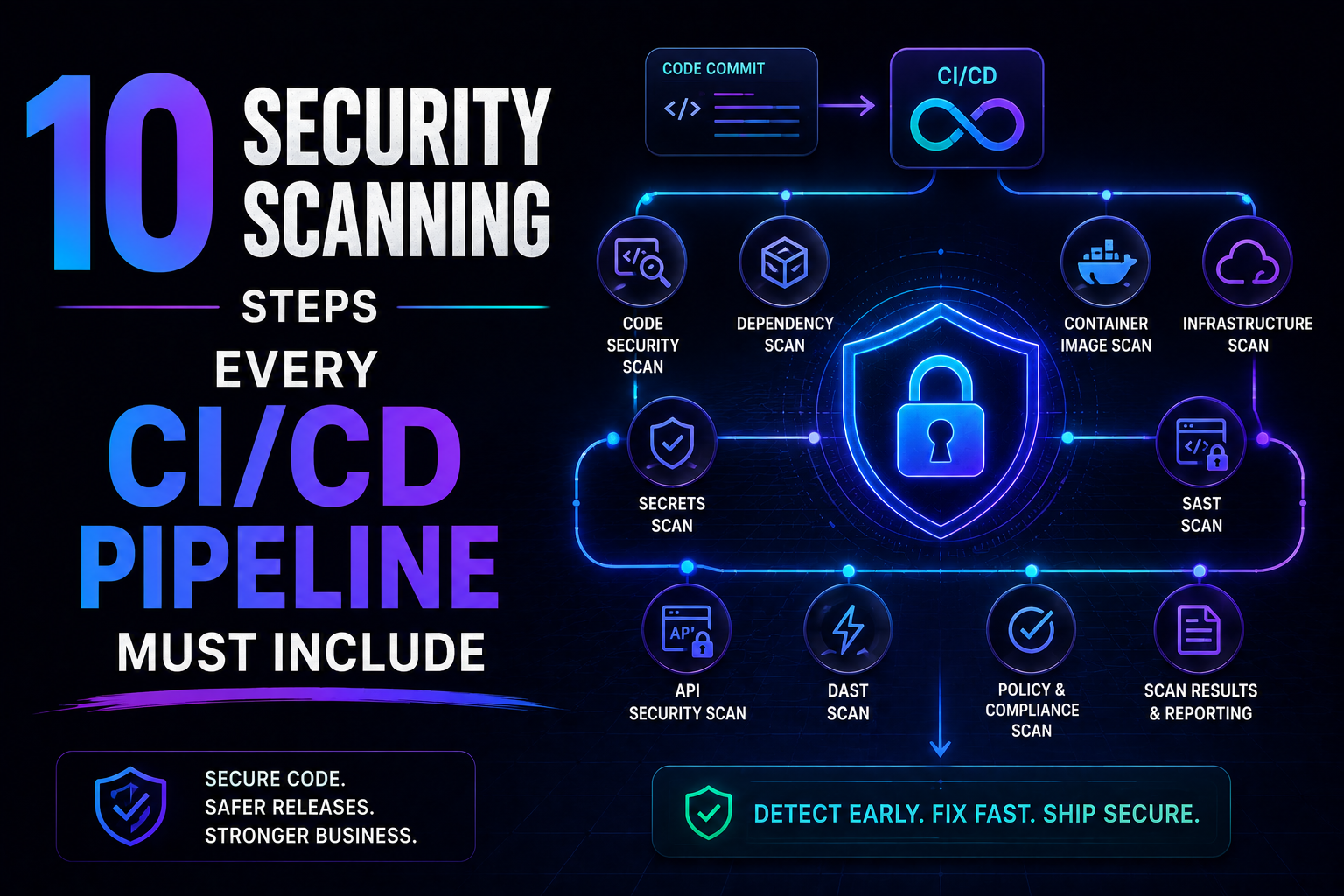
158SAST, SCA, container scanning, DAST, runtime verification – 10 security steps every CI/CD pipeline needs in 2026. Open source tools, real examples, and a rollout timeline. Stop shipping vulnerabilities.